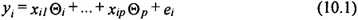|
|
|
|||
        |
|
|
|
[an error occurred while processing this directive]
10.2 The LS and LMS MethodsEmpirical computer models can be constructed using regression analysis. The purpose of regression analysis is to fit equations of a very general standard form to observed variables. Although regression analysis is not employed in its pure sense in the models discussed in this chapter, the idea of using the least squares and least median squares regression criteria is employed. The result of the modeling effort in this chapter is an empirical computer model that can then be used to perform interpolation and/or extrapolation on the system. The classical linear model assumes an equation of the form
for i = 1,…,N where N is the number of data points. The variables xi1,...,xip are the independent variables, and yi is the dependent variable. In classical statistics, the error term, ei, is assumed to be normally distributed with mean zero and unknown standard deviation, σ. One then estimates the vector of unknown parameters Θ from the N data points (xi, yi). Applying a regression estimator (which can be computed analytically for a number of model forms) to such a data set yields a set of estimated regression coefficients Θ’. Although the actual regression coefficients, Θ, are unknown, the independent variables can be multiplied by the estimated regression coefficients to obtain
where y’i is called the predicted value of yi. The residual ri of the ith case is the difference between what is actually observed and what is predicted:
LS curve fitting is the most popular regression approach and dates back to Gauss and Legendre (see Plackett, 1972 for some historical discussion). In the LS method, the sum of the squares of the residuals is minimized. Mathematically, the objective is to minimize
The idea is to optimize the fit by making the sum of the residuals as small as possible. The method’s popularity is easily understood when one realizes that at the time of the method’s conception there were no computers, and the fact that the estimated regression coefficients could be calculated explicitly via some matrix algebra, made LS the most practical approach to curve fitting. Even today, most statistical packages utilize the LS method because of tradition and speed of computation. Actually, there are a number of situations for which LS curve fitting is more than adequate. However, there is a situation for which the method is not suitable. A major weakness of the LS method is apparent when the data set that is being fitted contains outliers. These data points, which for one reason or another do not fit the assumed form of the model, can cause the LS method to give bad results. A single outlier can dramatically affect the results of the LS method. Generally, the number of outliers it takes to contaminate a method is defined by a breakdown point. The breakdown point is the largest fraction of contamination that can cause the estimator to take on values arbitrarily far from the assumed model. For the LS method, the breakdown point tends to zero, which means that only one outlier is needed to cause the method to give inappropriate results. Under tightly controlled conditions (or when some pre-screening is performed), the number of outliers that are present in a data set can be minimized if the data points have at most three dimensions (Rousseeuw and Leroy, 1987). However, in a number of real-time engineering applications, data sets cannot be adequately purged of outliers. Fortunately, there is a regression technique that is capable of handling the occurrence of outliers more efficiently than the LS method. The LMS method of regression minimizes the median squared residual. An estimator is used to compute each of the N residuals and the median residual is found. It is this median residual that is minimized. The LMS method has a breakdown point of 50 pct since the points are sorted and the poorest half of the points do not influence the estimator. As it turns out, this estimator is very robust with respect to outliers. However, the method is not without its problems. When the data set is large, the method used at present to develop an LMS model can take a long time to converge. This occurs because the algorithm is based on examining the possible combinations of pairs of the data points, and for each combination a model is computed that includes performing a computer sort. There are situations wherein it is infeasible to examine all of the possible combinations. In such instances the number of possibilities considered must be reduced in some meaningful way. However, the savings gained in computational time can be offset by a failure to locate the best possible solution. Additionally, this approach to LMS regression is limited by the fact that the modeling equation must pass through two of the data points exactly in high order equations. There are, however, situations in which the best fit does not pass directly through any of the data points. The remainder of this chapter focuses on using a GA to locate the estimator for a LMS regression; here estimator refers to the constants in the chosen model equation. Since we have addressed the requirements of the GA in several places previously, the details of the application are summarized. Results are provided that demonstrate the effectiveness of using GA LMS for developing empirical computer models. Most of the examples come from the mineral processing industry, but the approach is applicable to many engineering problems.
Copyright © CRC Press LLC
|
 |
         |
|