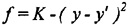|
|
|
|||
        |
|
|
|
[an error occurred while processing this directive]
5.3 How Genetic Algorithms WorkEffective search algorithms must, in some way, exploit information about the search space. Derivative-based search schemes utilize information about gradients to direct their walk through the search space. This exploitation of derivative information often leads to an effective search algorithm. However, there are problems in which derivative information is misleading, and thus derivative searches fail. GAs tend to exploit information in a radically different way. GAs work with binary representations of the parameters. Each binary string represents a single point in the search space. Each population of strings (each generation) represents a cloud of points in the search space. The GA operators of reproduction, crossover, and mutation serve to reshape the cloud of points from one generation to the next and to concentrate it in the region of the solution. No derivative information is used. The only information a GA exploits is information contained in the fitness values. The fitness values are used by the GA to find regions of the search space that contain highly fit points (good solutions). This information is used by the reproduction operator to bias the cloud of points in a generation toward or into these regions. Thus, the fitness information is exploited and guides the search. GAs effectively balance the two key aspects of any search: (1) exploitation and (2) exploration. Exploitation uses local information to refine local solutions, while exploration is a way of insuring that global objectives are met; here, global is used to reference the entire search space. Effective search techniques must balance the concepts of exploitation and exploration. Derivative-based searches tend to rely exclusively on exploitation. They have no mechanism for recognizing when their search has become trapped in a local optimum. Monte-Carlo searches, on the other hand, tend to rely exclusively on exploration and totally neglect exploitation; Monte-Carlo techniques are basically random walks through a space. GAs actually balance these two ideas quite well. Reproduction exploits fitness information to bias the points being considered toward high-fitness regions. Crossover and mutation, on the other hand, do not rely on fitness information. These two operators place randomly generated points in the population. Crossover and mutation allow for the consideration of points far from the current local optimum. GAs exhibit some fundamental differences from more-conventional search techniques, most of which are calculus-based. These differences include:
5.4 Genetic Algorithm Applied to Least-Squares Curve-Fitting ProblemsIn this section, a simple GA is used to solve two additional least-squares curve-fitting problems. The purpose of including these additional examples is to instill confidence in the reader that a genetic algorithm can be used to solve curve-fitting problems that are more difficult than the simple line presented in section 5.2. In both problems, the details of the genetic algorithm’s application are consistent with the example of section 5.2. Thus, only the results are presented. In both problems the GA finds a solution that is better than previously found using alternative techniques. 5.4.1 Preliminary ConsiderationsBefore considering the two specific problems, two points concerning the application of the GA must be addressed. There are basically two decisions to be made when applying a GA to any given problem: (1) how to code the parameters of the problem as a finite string, and (2) how to evaluate the merit of each string (each parameter set). The method for coding the strings discussed previously will again be used here. A linearly mapped, binary, concatenated coding scheme is used. In this scheme, the search parameters are represented as binary strings. Substrings representing the individual parameters are concatenated to form the full strings. The binary representations are mapped linearly between minimum and maximum parameter values. Consider the question of how to evaluate each string. In least-squares curve-fitting problems, the objective is to minimize the sum of the squares of the distances between a curve of a given form and the data points. Thus, if y is the ordinate of one of the data points, and y’ is the ordinate of the corresponding point on the curve produced by the modeling equation, the objective of least-squares curve fitting is to make (y - y’)2 a minimum. This square of the error, which is to be minimized, affords a good measure of the quality of the solution. However, the GA seeks to maximize the fitness. Again, the minimization problem must be transformed into a maximization problem. Here, again, the error is simply subtracted from a large positive constant (K) so that
yields a maximization problem. The selection of an appropriate coding and the determination of a fitness representation are the only aspects of a GA that are problem specific. Once these two decisions have been made, every problem is the same to a GA. The GA generates populations of strings, evaluates them, and uses these evaluations to produce subsequent generations of more highly fit strings. Thus, the GA is a very flexible search method. The simple GA described earlier has been programmed in the C programming language by modifying the code found in Goldberg (1989). The GA is run in these examples with the following parameters:
These values are consistent with De Jong’s suggestions (1975) for moderate population size, high crossover probability, and low mutation probability.
Copyright © CRC Press LLC
|
 |
         |
|