|
|
|
|||
        |
|
|
|
[an error occurred while processing this directive]
(Note the similarity with the 3-round attack.)
The input x-ors for S2, S5, S6, S7 and S8 are all 000000, and hence the output x-ors are 0000 for these five S-boxes in round 4. This means that we can compute the output x-ors of these five S-boxes in round 6 from Equation (3.4). So, suppose we compute
where each Ci is a bitstring of length four. Then with probability 1/16, it will be the case that
and
can be computed from the ciphertexts, as indicated in Figure 3.13. We would like to determine the 30 key bits in J2, J5, J6, J7 and J8 as we did in the 3-round attack. The problem is that the hypothesized output x-or for round 6 is correct only with probability 1/16. So 15/16 of the time we will obtain random garbage rather than possible key bits. We somehow need to be able to determine the correct key from the given data, 15/16 of which is incorrect. This might not seem very promising, but fortunately our prospects are not as bleak as they initially appear. DEFINITION 3.6 Suppose
We expect that about 1/16 of our pairs are right pairs and the rest are wrong pairs with respect to our 3-round characteristic. Our strategy is to compute Ej, We can often identify a wrong pair by this method: If |testj| = 0, for any j ∈ {2, 5, 6, 7, 8}, then we necessarily have a wrong pair. Now, given a wrong pair, we might expect that the probability that |testj| = 0 for a particular j is approximately 1/5. This is a reasonable assumption since
Copyright © CRC Press LLC
|
 |
         |
|
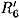 is known. From the characteristic, we estimate that
is known. From the characteristic, we estimate that 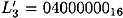 and
and 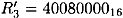 with probability 1/16. If this is in fact the case, then the input x-or for the S-boxes in round 4 can be computed by the expansion function to be:
with probability 1/16. If this is in fact the case, then the input x-or for the S-boxes in round 4 can be computed by the expansion function to be: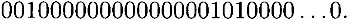
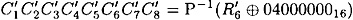
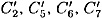 and
and 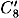 are respectively the output x-ors of S2, S5, S6, S7 and S8 in round 6. The inputs to these S-boxes in round 6 can be computed to be E2, E5, E6, E7 and E8, and
are respectively the output x-ors of S2, S5, S6, S7 and S8 in round 6. The inputs to these S-boxes in round 6 can be computed to be E2, E5, E6, E7 and E8, and 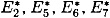 and
and 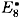 , where
, where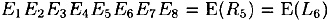
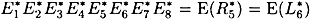
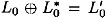 and
and 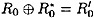 . We say that the pair of plaintexts L0R0 and
. We say that the pair of plaintexts L0R0 and 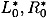 is right pair with respect to a characteristic if
is right pair with respect to a characteristic if 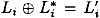 and
and 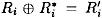 for all i, 1 ≤ i ≤ n. The pair is defined to be a wrong pair, otherwise.
for all i, 1 ≤ i ≤ n. The pair is defined to be a wrong pair, otherwise.)
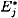 , and
, and 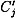 , as described above, and then to determine
, as described above, and then to determine 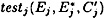 , for j = 2, 5, 6, 7, 8. If we start with a right pair, then the correct key bits for each Jj will be included in the set testj. If the pair is a wrong pair, then the value of
, for j = 2, 5, 6, 7, 8. If we start with a right pair, then the correct key bits for each Jj will be included in the set testj. If the pair is a wrong pair, then the value of 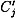 will be incorrect, and it seems reasonable to hypothesize that each set testj will be essentially random.
will be incorrect, and it seems reasonable to hypothesize that each set testj will be essentially random.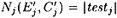 and, as mentioned earlier, the probability that
and, as mentioned earlier, the probability that 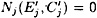 is approximately 1/5. The probability that all five testj’s have positive cardinality is estimated to be
is approximately 1/5. The probability that all five testj’s have positive cardinality is estimated to be 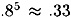 , so the probability that at least one testj has zero cardinality is about .67. So we expect to eliminate about 2/3 of the wrong pairs by this simple observation, which we call the filtering operation. The proportion of right pairs that remain after filtering is approximately
, so the probability that at least one testj has zero cardinality is about .67. So we expect to eliminate about 2/3 of the wrong pairs by this simple observation, which we call the filtering operation. The proportion of right pairs that remain after filtering is approximately