| Алгоритм LZW
Название алгоритм получил по первым буквам фамилий его
разработчиков — Lempel, Ziv и Welch. Сжатие в нем, в отличие от RLE, осуществляется
уже за счет одинаковых цепочек байт.
Алгоритм LZ
Существует довольно большое семейство LZ-подобных алгоритмов,
различающихся, например, методом поиска повторяющихся цепочек. Один из
достаточно простых вариантов этого алгоритма, например, предполагает, что
во входном потоке идет либо пара <счетчик, смещение относительно текущей
позиции>, либо просто <счетчик> “пропускаемых” байт и сами значения
байтов (как во втором варианте алгоритма RLE). При разархивации для пары
<счетчик, смещение> копируются <счетчик> байт из выходного массива,
полученного в результате разархивации, на <смещение> байт раньше, а
<счетчик> (т.е. число равное счетчику) значений “пропускаемых” байт
просто копируются в выходной массив из входного потока. Данный алгоритм
является несимметричным по времени, поскольку требует полного перебора
буфера при поиске одинаковых подстрок. В результате нам сложно задать большой
буфер из-за резкого возрастания времени компрессии. Однако потенциально
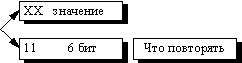
построение алгоритма, в котором на <счетчик> и на <смещение> будет
выделено по 2 байта (старший бит старшего байта счетчика — признак повтора
строки / копирования потока), даст нам возможность сжимать все повторяющиеся
подстроки размером до 32Кб в буфере размером 64Кб.

При этом мы получим увеличение размера файла в худшем
случае на 32770/32768 (в двух байтах записано, что нужно переписать в выходной
поток следующие 215 байт), что совсем неплохо. Максимальный
коэффициент сжатия составит в пределе 8192 раза. В пределе, поскольку максимальное
сжатие мы получаем, превращая 32Кб буфера в 4 байта, а буфер такого размера
мы накопим не сразу. Однако, минимальная подстрока, для которой нам выгодно
проводить сжатие, должна состоять в общем случае минимум из 5 байт, что
и определяет малую ценность данного алгоритма. К достоинствам LZ можно
отнести чрезвычайную простоту алгоритма декомпрессии.
Упражнение: Предложите другой вариант алгоритма
LZ, в котором на пару <счетчик, смещение> будет выделено 3 байта, и
подсчитайте основные характеристики своего алгоритма.
Алгоритм LZW
Рассматриваемый нами ниже вариант алгоритма будет использовать
дерево для представления и хранения цепочек. Очевидно, что это достаточно
сильное ограничение на вид цепочек, и далеко не все одинаковые подцепочки
в нашем изображении будут использованы при сжатии. Однако в предлагаемом
алгоритме выгодно сжимать даже цепочки, состоящие из 2 байт.
Процесс сжатия выглядит достаточно просто. Мы считываем
последовательно символы входного потока и проверяем, есть ли в созданной
нами таблице строк такая строка. Если строка есть, то мы считываем следующий
символ, а если строки нет, то мы заносим в поток код для предыдущей найденной
строки, заносим строку в таблицу и начинаем поиск снова.
Функция InitTable() очищает таблицу и помещает
в нее все строки единичной длины.
InitTable();
CompressedFile.WriteCode(СlearCode);
CurStr=пустая строка;
while(не ImageFile.EOF()){ //Пока не конец файла
C=ImageFile.ReadNextByte();
if(CurStr+C есть в таблице)
CurStr=CurStr+С;//Приклеить
символ к строке
else {
code=CodeForString(CurStr);//code-не
байт!
CompressedFile.WriteCode(code);
AddStringToTable
(CurStr+С);
CurStr=С;
// Строка из одного символа
}
}
code=CodeForString(CurStr);
CompressedFile.WriteCode(code);
CompressedFile.WriteCode(CodeEndOfInformation);
Как говорилось выше, функция InitTable() инициализирует
таблицу строк так, чтобы она содержала все возможные строки, состоящие
из одного символа. Например, если мы сжимаем байтовые данные, то таких
строк в таблице будет 256 (“0”, “1”, ... , “255”). Для кода очистки (ClearCode)
и кода конца информации (CodeEndOfInformation) зарезервированы
значения 256 и 257. В рассматриваемом варианте алгоритма используется 12-битный
код, и, соответственно, под коды для строк нам остаются значения от 258
до 4095. Добавляемые строки записываются в таблицу последовательно, при
этом индекс строки в таблице становится ее кодом.
Функция ReadNextByte() читает символ из файла.
Функция WriteCode() записывает код (не равный по размеру байту)
в выходной файл. Функция AddStringToTable() добавляет новую строку
в таблицу, приписывая ей код. Кроме того, в данной функции происходит обработка
ситуации переполнения таблицы. В этом случае в поток записывается код предыдущей
найденной строки и код очистки, после чего таблица очищается функцией InitTable().
Функция CodeForString() находит строку в таблице и выдает код
этой строки.
Пример:
Пусть мы сжимаем последовательность 45, 55, 55, 151, 55,
55, 55. Тогда, согласно изложенному выше алгоритму, мы поместим в выходной
поток сначала код очистки <256>, потом добавим к изначально пустой строке
“45” и проверим, есть ли строка “45” в таблице. Поскольку мы при инициализации
занесли в таблицу все строки из одного символа, то строка “45” есть в таблице.
Далее мы читаем следующий символ 55 из входного потока и проверяем, есть
ли строка “45, 55” в таблице. Такой строки в таблице пока нет. Мы заносим
в таблицу строку “45, 55” (с первым свободным кодом 258) и записываем в
поток код <45>. Можно коротко представить архивацию так:
“45” — есть в таблице;
“45, 55” — нет. Добавляем в таблицу <258>“45, 55”. В поток:
<45>;
“55, 55” — нет. В таблицу: <259>“55, 55”. В поток: <55>;
“55, 151” — нет. В таблицу: <260>“55, 151”. В поток: <55>;
“151, 55” — нет. В таблицу: <261>“151, 55”. В поток: <151>;
“55, 55” — есть в таблице;
“55, 55, 55” — нет. В таблицу: “55, 55, 55” <262>. В поток:
<259>;
Последовательность кодов для данного примера, попадающих
в выходной поток: <256>, <45>, <55>, <55>, <151>, <259>.
Особенность LZW заключается в том, что для декомпрессии
нам не надо сохранять таблицу строк в файл для распаковки. Алгоритм построен
таким образом, что мы в состоянии восстановить таблицу строк, пользуясь
только потоком кодов.
Мы знаем, что для каждого кода надо добавлять в таблицу
строку, состоящую из уже присутствующей там строки и символа, с которого
начинается следующая строка в потоке.
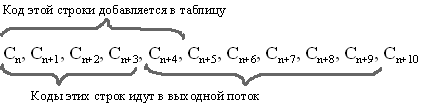
Алгоритм декомпрессии, осуществляющий эту операцию, выглядит
следующим образом:
code=File.ReadCode();
while(code != СodeEndOfInformation){
if(code = СlearСode) {
InitTable();
code=File.ReadCode();
if(code
= СodeEndOfInformation)
{закончить работу};
ImageFile.WriteString(StrFromTable(code));
old_code=code;
}
else {
if(InTable(code))
{
ImageFile.WriteString(FromTable(code));
AddStringToTable(StrFromTable(old_code)+
FirstChar(StrFromTable(code)));
old_code=code;
}
else {
OutString= StrFromTable(old_code)+
FirstChar(StrFromTable(old_code));
ImageFile.WriteString(OutString);
AddStringToTable(OutString);
old_code=code;
}
}
}
Здесь функция ReadCode() читает очередной код
из декомпрессируемого файла. Функция InitTable() выполняет те
же действия, что и при компрессии, т.е. очищает таблицу и заносит в нее
все строки из одного символа. Функция FirstChar() выдает нам первый
символ строки. Функция StrFromTable() выдает строку из таблицы
по коду. Функция AddStringToTable() добавляет новую строку в таблицу
(присваивая ей первый свободный код). Функция WriteString() записывает
строку в файл.
Замечание 1. Как вы могли заметить, записываемые
в поток коды постепенно возрастают. До тех пор, пока в таблице не появится,
например, в первый раз код 512, все коды будут меньше 512. Кроме того,
при компрессии и при декомпрессии коды в таблице добавляются при обработке
одного и того же символа, т.е. это происходит “синхронно”. Мы можем воспользоваться
этим свойством алгоритма для того, чтобы повысить степень компрессии. Пока
в таблицу не добавлен 512 символ, мы будем писать в выходной битовый поток
коды из 9 бит, а сразу при добавлении 512 — коды из 10 бит. Соответственно
декомпрессор также должен будет воспринимать все коды входного потока 9-битными
до момента добавления в таблицу кода 512, после чего будет воспринимать
все входные коды как 10-битные. Аналогично мы будем поступать при добавлении
в таблицу кодов 1024 и 2048. Данный прием позволяет примерно на 15% поднять
степень компрессии:

Замечание 2. При сжатии изображения нам важно обеспечить быстроту
поиска строк в таблице. Мы можем воспользоваться тем, что каждая следующая
подстрока на один символ длиннее предыдущей, кроме того, предыдущая строка
уже была нами найдена в таблице. Следовательно, достаточно создать список
ссылок на строки, начинающиеся с данной подстроки, как весь процесс поиска
в таблице сведется к поиску в строках, содержащихся в списке для предыдущей
строки. Понятно, что такая операция может быть проведена очень быстро.
Заметим также, что реально нам достаточно хранить в таблице только
пару <код предыдущей подстроки, добавленный символ>.
Этой информации вполне достаточно для работы алгоритма. Таким образом,
массив от 0 до 4095 с элементами <код предыдущей подстроки; добавленный
символ; список ссылок на строки, начинающиеся с этой строки> решает поставленную
задачу поиска, хотя и очень медленно.
На практике для хранения таблицы используется такое же
быстрое, как в случае списков, но более компактное по памяти решение —
хэш-таблица. Таблица состоит из 8192 (213) элементов. Каждый
элемент содержит <код предыдущей подстроки; добавленный символ; код
этой строки>. Ключ для поиска длиной в 20 бит формируется с использованием
двух первых элементов, хранимых в таблице как одно число (key). Младшие
12 бит этого числа отданы под код, а следующие 8 бит под значение символа.
В качестве хэш-функции при этом используется:
Index(key)= ((key >> 12) ^ key) & 8191;
Где >> — побитовый сдвиг вправо (key >> 12 — мы получаем
значение символа), ^ — логическая операция побитового исключающего ИЛИ,
& логическое побитовое И.
Таким образом, за считанное количество сравнений мы получаем
искомый код или сообщение, что такого кода в таблице нет.
Подсчитаем лучший и худший коэффициенты компрессии для
данного алгоритма. Лучший коэффициент, очевидно, будет получен для цепочки
одинаковых байт большой длины (т.е. для 8-битного изображения, все точки
которого имеют, для определенности, цвет 0). При этом в 258 строку таблицы
мы запишем строку “0, 0”, в 259 — “0, 0, 0”, ... в 4095 — строку из 3839
(=4095-256) нулей. При этом в поток попадет (проверьте по алгоритму!) 3840
кодов, включая код очистки. Следовательно, посчитав сумму арифметической
прогрессии от 2 до 3839 (т.е. длину сжатой цепочки) и поделив ее на 3840*12/8
(в поток записываются 12-битные коды), мы получим лучший коэффициент компрессии.
Упражнение: Вычислить точное значение лучшего
коэффициента компрессии. Более сложное задание: вычислить тот же коэффициент
с учетом замечания 1.
Худший коэффициент будет получен, если мы ни разу не встретим
подстроку, которая уже есть в таблице (в ней не должно встретиться ни одной
одинаковой пары символов).
Упражнение: Составить алгоритм генерации таких
цепочек. Попробовать сжать полученный таким образом файл стандартными архиваторами
(zip, arj, gz). Если вы получите сжатие, значит алгоритм генерации написан
неправильно.
В случае, если мы постоянно будем встречать новую подстроку,
мы запишем в выходной поток 3840 кодов, которым будет соответствовать строка
из 3838 символов. Без учета замечания 1 это составит увеличение файла почти
в 1.5 раза.
LZW реализован в форматах GIF и TIFF.
Характеристики алгоритма LZW:
Коэффициенты компрессии: Примерно 1000, 4, 5/7
(Лучший, средний, худший коэффициенты). Сжатие в 1000 раз достигается только
на одноцветных изображениях размером кратным примерно 7 Мб.
Класс изображений: Ориентирован LZW на 8-битные
изображения, построенные на компьютере. Сжимает за счет одинаковых подцепочек
в потоке.
Симметричность: Почти симметричен, при условии
оптимальной реализации операции поиска строки в таблице.
Характерные особенности: Ситуация, когда алгоритм
увеличивает изображение, встречается крайне редко. LZW универсален — именно
его варианты используются в обычных архиваторах.
|