|
|
|
|
2.10. Очереди и стеки
Очередь и стек представляют собой структуры данных с фиксированными механизмами занесения и выбора элементов. Возможны реализации очереди и стека на базе регулярных или списковых структур данных. Соответственно представлению изменяется реализация механизмов обработки структур. Однако определяющими являются следующие принципы: очередь предполагает занесение нового элемента в конец, а выбор с начала списка (FIFO √ First In First Out); в стек элемент заносится в начало и выбирается также сначала (LIFO √ Last In First Out).
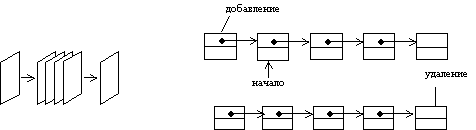
Очередь на базе списка
Из механизма FIFO следует, что в очереди доступны два элемента √ первый и последний.
простая очередь
Рис. 7. Организация дека на основе линейного списка [3].
Структура данных, представляющая очередь, могла бы выглядеть следующим образом:
type
TypeOfElem= {};
Assoc= ^ElementOfQueue;
ElementOfQueue= record
Elem: TypeOfElem;
NextElem: Pointer
end;
Queue= Assoc;
Рассмотрим реализацию основных операций над очередью.
Создание (очистка) очереди
Для создания новой пустой или очистки существующей очереди достаточно присвоить указателям на первый и последний элементы значение nil.
procedure CreateQueue ( var FirstElem, LastElem: Queue);
begin
FirstElem:= nil;
LastElem:= nil
end;
Проверка очереди на пустоту
Условием пустоты очереди является значения указателей на первый и последний элементы, равные nil.
function QueueIsClear( var FirstElem, LastElem: Queue ): Boolean;
begin
QueueIsClear:= ( FirstElem= nil ) and ( LastElem= nil )
end;
Включение элемента в очередь
Для включения элемента в очередь, необходимо создать новый элемент типа очередь, затем инициализировать его информационное поле. В заключение изменить его указатель и указатель на последний элемент очереди так, чтобы последним стал новый элемент.
procedure IncludeInQueue( var FirstElem, LastElem: Queue; NewElem: TypeOfElem);
var
ServiceVar: Queue;
begin
{создание нового элемента}
new( ServiceVar );
ServiceVar^.Elem:= NewElem;
ServiceVar^.NextElem:= nil;
if ( FirstElem= nil ) and ( LastElem= nil ) then begin
{создать очередь из одного элемента}
FirstElem:= ServiceVar;
LastElem:= ServiceVar
end
else begin
{созданный элемент поместить в конец очереди}
LastElem^.NextElem:= ServiceVar;
LastElem:= ServiceVar
end
end;
Выбор элемента из очереди
При выборе элемента из очереди информационное поле первого ее элемента должно быть присвоено результирующей переменной, а сам элемент должен быть исключен из очереди и удален. Здесь необходима также проверка на то, являлся ли этот элемент в очереди единственным, и если да, то необходимо соответствующим образом изменить указатель на последний элемент.
procedure SelectFromQueue( var FirstElem, LastElem: Queue; var Result: TypeOfElem);
var
ServiceVar: Queue;
begin
if not ( ( FirstElem= nil ) and ( LastElem= nil ) ) then begin
Result:= FirstElem^.Elem;
ServiceVar:= FirstElem;
{убираем 1-ый элемент из очереди}
FirstElem:= FirstElem^.NextElem;
{был ли это последний элемент}
if FirstElem= nil then
LastElem:= nil;
dispose( ServiceVar )
end
end;
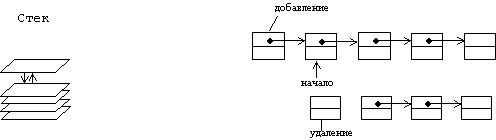
Стек на базе списка
Из механизма LIFO следует, что в стеке доступен только последний занесенный его элемент √ так называемая вершина стека. Главный элемент, представляющий весь список как единый объект, в случае стека оказывается лишним, его роль выполняет вершина стека. Элемент, занесенный в стек раньше других имеет ссылку nil.
Рис. 8. Организация стека на основе линейного списка [3].
Структура данных, представляющая стек, могла бы выглядеть следующим образом:
type
TypeOfElem= {};
Assoc= ^ElementOfStack;
ElementOfStack= record
Elem: TypeOfElem;
NextElem: Pointer
end;
Stack= Assoc;
Рассмотрим реализацию основных операций над стеком.
Создание (очистка) стека
Для создания нового пустого или очистки существующего стека достаточно присвоить указателю на первый его элемент (вершину) значение nil.
procedure CreateStack ( var StackHead: Stack);
begin
StackHead:= nil
end;
Проверка стека на пустоту
Условием пустоты стека является значение его вершины, равное nil.
function StackIsClear( var StackHead: Stack ): Boolean;
begin
StackIsClear:= ( StackHead= nil )
end;
Занесение элемента в стек
Для включения элемента в стек, необходимо создать новый элемент типа стек, затем инициализировать его информационное поле. В заключение изменить его указатель и указатель на первый элемент стека так, чтобы первым стал новый элемент.
procedure IncludeInStack( var StackHead: Stack; NewElem: TypeOfElem );
var
ServiceVar: Stack;
begin
{создание нового элемента}
 new( ServiceVar );
ServiceVar^.Elem:= NewElem;
{созданный элемент сделать вершиной стека}
ServiceVar^.NextElem:= StackHead;
StackHead:= ServiceVar
end;
Выбор элемента из стека
При выполнении этой операции информационное поле элемента, находящегося в вершине стека, должно быть присвоено в качестве значения некоторой переменой, а сам элемент должен быть исключен из стека и уничтожен.
procedure SelectFromStack( var StackHead: Stack; var Result: TypeOfElem );
var
ServiceVar: Assoc;
begin
if StackHead <> nil then begin
{выбор элемента из вершины}
Result:= StackHead^.Elem;
{запоминание ссылки на старую вершину}
ServiceVar:= StackHead;
{исключение из стека и уничтожение элемента}
StackHead:= StackHead^.NextElem;
dispose( ServiceVar )
end
end;
Необходимо обратить внимание на введение вспомогательной переменной ссылочного типа ServiceVar для осуществления удаления элемента. Типична ошибка, связанная с попыткой решить эту задачу через dispose( StackHead ).
Разберем решение типичной задачи, связанной с обработкой стека.
Текст задания
Используя стек (считать уже описанными тип Stack с информационным элементом типа Char, функцию StackIsClear (проверка пустоты стека) и процедуры CreateStack (очистка стека), IncludeInStack (вставка элемента в стек), SelectFromStack (выборка элемента из стека)) решить следующую задачу: в текстовом файле f записана без ошибок формула следующего вида:
<формула>::= <цифра>|M(<формула>,<формула>)|m(<формула>,<формула>)
цифра::= 0|1|2|3|4|5|6|7|8|9
где M обозначает функцию max, а m √ min. Вычислить (как целое число) значение данной формулы (например, M( 5, m( 6, 8)): 6).
Решение
program StackSample;
type
FileType= File of Char;
var
Source: FileType;
function formula( var t: FileType ): integer;
type
TypeOfElem= Char;
Assoc= ^ElementOfStack;
ElementOfStack= record
Elem: TypeOfElem;
NextElem: Pointer
end;
Stack= Assoc;
var
S: Stack;
c, op, x, y: char;
procedure CreateStack ( var StackHead: Stack);
begin
StackHead:= nil
end;
function StackIsClear( var StackHead: Stack ): Boolean;
begin
StackIsClear:= ( StackHead= nil )
end;
procedure IncludeInStack( var StackHead: Stack; NewElem: TypeOfElem );
var
ServiceVar: Stack;
begin
{создание нового элемента}
new( ServiceVar );
ServiceVar^.Elem:= NewElem;
{созданный элемент сделать вершиной стека}
ServiceVar^.NextElem:= StackHead;
StackHead:= ServiceVar
end;
procedure SelectFromStack( var StackHead: Stack; var Result: TypeOfElem );
var
ServiceVar: Assoc;
begin
if StackHead <> nil then begin
{выбор элемента из вершины}
Result:= StackHead^.Elem;
{запоминание ссылки на старую вершину}
ServiceVar:= StackHead;
{исключение из стека и уничтожение элемента}
StackHead:= StackHead^.NextElem;
dispose( ServiceVar )
end
end;
begin
reset( t );
CreateStack( S );
while not eof( t ) do begin
read(t, c);
{обработка очередной литеры текста (литеры ╚(╩ и ╚,╩ игнорируются)}
if c in ['0'..'9','M','m'] then IncludeInStack( S, c)
else
if c= ')' then begin {конец формулы вида p(x, y)}
{в конце стека находится тройка op x y, она удаляется
из стека, выполняется операция op и результат
записывается в стек}
SelectFromStack( S, y );
SelectFromStack( S, x );
SelectFromStack( S, op );
case op of
'M'{max}: if x > y then c:= x else c:= y;
'm'{min}: if x < y then c:= x else c:= y
end;
IncludeInStack( S, c )
end
end; {of while}
{в стеке осталась одна цифра √ значение всей формулы; цифра переводится в целое число}
SelectFromStack( S, c );
formula:= ord( c ) - ord( '0' )
end;
begin
assign( Source, 'c:\temp\source.txt' );
writeln( Formula( Source ) );
end.
Варианты заданий
1). Очереди
1. Type FR= file of real; За один просмотр файла f типа FR и без использования дополнительных файлов вывести элементы файла f в следующем порядке: сначала- все числа, меньшие a, затем- все остальные числа, сохраняя исходный взаимный порядок в каждой из этих трех групп чисел (a заданное число).
2. Type FR= file of real; За один просмотр файла f типа FR и без использования дополнительных файлов вывести элементы файла f в следующем порядке: сначала все числа из отрезка [a, b], и затем - все остальные числа, сохраняя исходный взаимный порядок в каждой из этих трех групп чисел (a и b- заданные числа a < b).
3. Содержимое текстового файла f, разделенное на строки, переписать в текстовый файл g, перенося при этом в конец каждой строки все входящие в нее цифры (с сохранением исходного взаимного порядка, как среди цифр, так и среди остальных литер строки).
4. Содержимое текстового файла f, разделенное на строки, переписать в текстовый файл g, перенося при этом в конец каждой строки все входящие в нее строчные гласные латинского алфавита (с сохранением исходного взаимного порядка, как среди гласных, так и среди остальных литер строки).
5. Содержимое текстового файла f, разделенное на строки, переписать в текстовый файл g, перенося при этом в конец каждой строки все входящие в нее символы ▒+▓, ▒-▒, ▒*▓ (с сохранением исходного взаимного порядка как среди этих символов, так и среди остальных литер строки).
6. type name= (George, Alex, Piter, Ann, Paul, John, Fred, Natalie, Robert); child= array [name, name] of boolean; children= file of name; Считая заданными имя n и массив d типа child (d[x]= true, если человек по имени y является ребенком человека по имени x), записать файл p типа children имена всех потомков человека с именем n в следующем порядке: сначала √ имена всех детей, затем √ всех его внуков, затем √ его правнуков и т.д.
7. Описать процедуру, которая по одной очереди строит две новых: Queue1 из положительных элементов и Queue2 - из остальных элементов очереди (TypeOfElem= real).
8. Описать процедуру, которая подсчитывает количество элементов очереди, у которых равные "соседи".
9. Описать процедуру, которая определяет, есть ли в очереди хотя бы один элемент, который равен следующему за ним элементу.
10. Описать процедуру, которая в очереди переставляет в обратном порядке все элементы между первыми последним вхождением элемента E, если E входит в L не менее двух раз.
11. Описать процедуру, которая удаляет из очереди первый отрицательный элемент, если такой есть.
12. Описать процедуру, которая из очереди, содержащего не менее двух элементов, удаляет все элементы, у которых одинаковые "соседи".
13. Описать процедуру, которая формирует очередь Queue, включив в нее по одному разу элементы, которые входят хотя бы в одну из очередей Queue1 или Queue2.
14. Описать процедуру, которая формирует очередь Queue, включив в нее по одному разу элементы, которые входят в очередь Queue1, но не входят в очередь Queue2.
15. Описать процедуру, которая формирует очередь Queue, включив в нее по одному разу элементы, которые входят в одну из очередей Queue1 и Queue2, но в то же время не входят в другую из них.
2). Стеки
16. Вывести содержимое текстового файла t, выписывая литеры каждой его строки в обратном порядке.
17. Проверить, является ли содержимое текстового файла t правильной записью формулы следующего вида
<формула>::= <терм> | <терм> + <формула> | <терм> - <формула>
<терм>::= <имя> | (<формула>) | [<формула>] | {<формула>}
<имя>::= x | y | z
18. В текстовом файле Log записано без ошибок логическое выражение (ЛВ) в следующей форме.
<ЛВ>::= true | false | ( <ЛВ>) | (<ЛВ> /\ <ЛВ>) | (<ЛВ> \/<ЛВ>),
где знаки , /\ и \/ обозначают соответственно отрицание, конъюнкцию и дизъюнкцию. Вычислить (как boolean) значение этого выражения.
19. В текстовом файле t записан текст, сбалансированный по круглым скобкам:
<текст>::= <пусто> | <элемент> <текст>
<элемент>::= <буква> | (<текст>)
Требуется для каждой пары соответствующих открывающей и закрывающей скобок вывести номера их позиций в тексте, упорядочив пары номеров в порядке возрастания номеров этих позиций закрывающих скобок.
20. Для задачи 19 вывести номера их позиций в тексте, упорядочив пары номеров в порядке возрастания номеров этих позиций открывающих скобок.
21. Под ╚выражением╩ будем понимать конструкцию следующего вида.
<текст>::= <терм> | <терм> <знак+√> <выражение>
<знак+√>::= + | √
<терм>::= <множитель> | <множитель>*<терм>
<множитель>::= <число> | <переменная> | (<выражение>) | <множитель>^<число>
<число>::= <цифра>
<переменная>::= <буква>
Где знак ^ обозначает возведение в степень. Постфиксной формой записи выражения a/\b называется запись, в которой знак операции размещен за операндами: ab/\.
Описать функцию value( postfix ), которая вычисляет как целое число значение выражения (без переменных), записанного в постфиксной форме в текстовом файле postfix. Использовать следующий алгоритм вычисления. Выражение просматривается слева направо. Если встречается операнд (число), то его значение (как целое) заносится в стек, а если встречается знак операции, то из стека извлекаются два последних элемента (это операнды данной операции), над ними выполняется операция и ее результат записывается в стек. В конце концов, в стеке останется только одно число √ значение всего выражения.
22. Описать процедуру translate( infix, postfix ), которая переводит выражение, записанное в обычной (инфиксной) форме в текстовом файле infix, в постфиксную форму и в таком виде записывает его в текстовый файл postfix. Использовать следующий алгоритм перевода. В стек записывается открывающая скобка, и выражение просматривается слева направо. Если встречается операнд (число или переменная), то он сразу переносится в файл postfix. Если встречается открывающая скобка, то она заносится в стек, а если встречается закрывающая скобка, то из стека извлекаются находящиеся там знаки операций до ближайшей открывающей скобки, которая также удаляется из стека, и все эти знаки (в порядке их извлечения) записываются в файл postfix. Когда встречается знак операции, то из стека извлекаются (до ближайшей скобки, которая сохраняется в стеке) знаки операций, старшинство которых больше или равно старшинству данной операции, и они записываются в файл postfix, после чего рассматриваемый знак заносится в стек. В заключение выполняются такие действия, как если бы встретилась закрывающая скобка.
23. Описать нерекурсивную процедуру infixprint( postfix ), которая печатает в обычной (инфиксной) форме выражение, записанное в постфиксной форме в текстовом файле postfix. (Лишние скобки желательно не печатать.)
24. Описать процедуру, которая по одному стеку строит два новых: Stack1 из положительных элементов и Stack2 - из остальных элементов (TypeOfElem= real).
25. Описать процедуру, которая подсчитывает количество элементов стека, у которых равные "соседи".
26. Описать процедуру, которая определяет, есть ли в стеке хотя бы один элемент, который равен следующему за ним элементу.
27. Описать процедуру, которая удаляет из стека первый отрицательный элемент, если такой есть.
28. Описать процедуру, которая формирует стек Stack, включив в него по одному разу элементы, которые входят хотя бы в один из стеков Stack1 или Stack2.
29. Описать процедуру, которая формирует стек Stack, включив в него по одному разу элементы, которые входят в стек Stack1, но не входят в стек Stack2.
30. Описать процедуру, которая формирует стек Stack, включив в него по одному разу элементы, которые входят в один из стеков Stack1 и Stack2, но в то же время не входят в другой из них.
|
|