 |
|

Cтруктуры данных. Хранение информации.
Слоёные списки
Слоёные списки - это связные списки, которые позволяют вам пропустить (skip) ненужные элементы, прыгнув сразу к нужному. Это позволяет преодолеть ограничения последовательного поиска, являющегося основным источником неэффективного поиска в списках. В то же время вставка и удаление остаются сравнительно эффективными. Оценка среднего времени поиска в таких списках есть O(lg n). Для наихудшего случая оценкой является O(n), но худший случай крайне маловероятен.
Эта структура очень удобна и сочетает простоту несбалансированного бинарного дерева с хорошими показателями AVL-tree.
Теория
Идея, лежащая в основе слоёных списков, очень напоминает метод, используемый при поиске имен в адресной книжке. Чтобы найти имя, вы помечаете буквой страницу, откуда начинаются имена, начинающиеся с этой буквы. На рис. 3.8, например, самый верхний список представляет обычный односвязный список. Добавив один "уровень" ссылок, мы ускорим поиск. Сначала мы идем по ссылкам уровня 1, затем, когда дойдем по нужного отрезка списка, пойдем по ссылкам нулевого уровня.
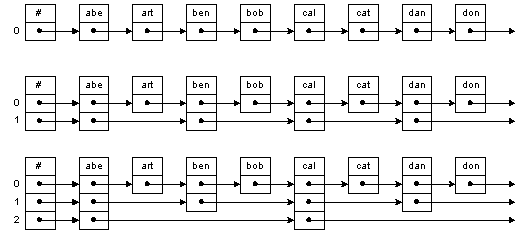
Рис. 3.8:Устройство слоёного списка
Эта простая идея может быть расширена - мы можем добавить нужное число уровней. Внизу на рис. 3.8 мы видим второй уровень, который позволяет двигаться еще быстрее первого. При поиске элемента мы двигаемся по этому уровню, пока не дойдем до нужного отрезка списка. Затем мы еще уменьшаем интервал неопределенности, двигаясь по ссылкам 1-го уровня. Лишь после этого мы проходим по ссылкам 0-го уровня.
Вставляя узел, мы должны будем определить количество исходящих от него ссылок. Эта проблема легче всего решается с использованием случайного механизма: при добавлении нового узла мы "бросаем монету", чтобы определить, нужно ли добавлять еще уровень. Например, мы можем добавлять очередные уровни до тех пор, пока выпадает "решка". Если реализован только один уровень, мы имеем дело фактически с обычным списком и время поиска есть O(n). Однако, если имеется достаточное число уровней, слоёный список можно считать деревом с корнем на высшем уровне, а для дерева время поиска есть O(lg n).
Поскольку реализация слоёных списков включает в себя случайный процесс, для времени поиска в них устанавливаются вероятностные границы. При обычных условиях эти границы довольно узки. Например, когда мы ищем элемент в списке из 1000 узлов, вероятность того, что время поиска окажется в 5 раз больше среднего, можно оценить как 1/1,000,000,000,000,000,000.
Реализация
skiplist.pas - Реализация скип-списков на Паскале с тестирующей процедурой.
skiplist.c - реализация работы со скип-списками на Си. Операторы typedef T, а также compLT и compEQ следует изменить так, чтобы они соответствовали данным, хранимым в узлах списка. Кроме того, понадобится выбрать константу MAXLEVEL; ее значение выбирается в зависимости от ожидаемого объема данных.
Функция initList вызывается в самом начале. Она отводит память под
заголовок списка и инициализирует его поля. Признаком того, что список пуст,
Функция insertNode создает новый узел и вставляет его в список.
Конечно, insertNode сначала отыскивает место в списке, куда узел
должен быть вставлен. В массиве update функция учитывает встретившиеся
ссылки на узлы верхних уровней. Эта информация в дальнейшем используется для
корректной установки ссылок нового узла. Для этого узла, с помощью генератора
случайных чисел, определяется значение newLevel, после чего отводится
память для узла. Ссылки вперед устанавливаются по информации, содержащей в
массиве update. Функция deleteNode удаляет узлы из списка и
освобождает занимаемую ими память. Она реализована аналогично функции
findNode и так же ищет в списке удаляемый узел.
 Вверх по странице, к оглавлению и навигации.
Вверх по странице, к оглавлению и навигации.