 |
|

Cтруктуры данных. Хранение информации.
Хеш-таблицы
Один из наиболее эффективных способов реализации словаря - хеш-таблица. Среднее время поиска элемента в ней есть O(1), время для наихудшего случая - O(n). Прекрасное изложение хеширования можно найти в работах Кормена[1990] и Кнута[1998].Чтобы читать статьи на эту тему, вам понадобится владеть соответствующей терминологией. Здесь описан метод, известный как связывание или открытое хеширование. Другой метод, известный как замкнутое хеширование или закрытая адресация, обсуждается ниже.
Теория. Открытое Хеширование
Хеш-таблица - это обычный массив с необычной адресацией, задаваемой хеш-функцией.
Например, на hashTable рис. 3.1 - это массив из 8 элементов. Каждый элемент представляет собой указатель на линейный список, хранящий числа. Хеш-функция в этом примере просто делит ключ на 8 и использует остаток как индекс в таблице. Это дает нам числа от 0 до 7 Поскольку для адресации в hashTable нам и нужны числа от 0 до 7, алгоритм гарантирует допустимые значения индексов.
Хеширование полезно, когда широкий диапазон возможных значений должен быть сохранен в малом объеме памяти, и нужен способ быстрого, практически произвольного доступа. Хэш-таблицы часто применяются в базах данных, и, особенно, в языковых процессорах типа компиляторов и ассемблеров, где они изящно обслуживают таблицы идентификаторов. В таких приложениях, таблица - наилучшая структура данных.
Так как всякий доступ к таблице должен быть произведен через хэш-функцию, функция должна удовлетворять двум требованиям: Она должна быть быстрой, и она должна порождать хорошие ключи для распределения элементов по таблице. Последнее требование минимизирует коллизии (случаи, когда два разных элемента имеют одинаковое значение хеш-функции) и педотвращает случай, когда элементы данных с близкими значениями попадают только в одну часть таблицы.
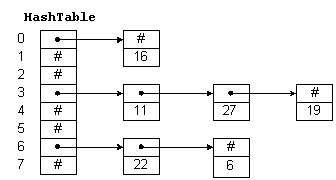
Рис. 3.1: Хеш-таблица
При добавлении элементов в хеш-таблицу выделяются куски динамической
памяти, которые организуются в виде связанных списков, каждый из которых
соответствует входу хеш-таблицы. Этот метод называется связыванием.
Если хеш-функция распределяет совокупность возможных ключей равномерно по множеству индексов, то хеширование эффективно разбивает множество ключей. Наихудший случай - когда все ключи хешируются в один индекс. При этом мы работаем с одним линейным списком, который и вынуждены последовательно сканировать каждый раз, когда что-нибудь делаем. Отсюда видно, как важна хорошая хеш-функция. Здесь мы рассмотрим лишь несколько из возможных подходов. При иллюстрации методов предполагается, что unsigned char располагается в 8 битах, unsigned short int - в 16, unsigned long int - в 32.
- Деление (размер таблицы hashTableSize - простое число). Этот метод использован в последнем примере. Хеширующее значение hashValue, изменяющееся от 0 до (hashTableSize - 1), равно остатку от деления ключа на размер хеш-таблицы. Вот как это может выглядеть:
- Мультипликативный метод (размер таблицы hashTableSize есть степень 2n). Значение key умножается на константу, затем от результата берется необходимое число битов. В качестве такой константы Кнут рекомендует золотое сечение (sqrt(5) - 1)/2 = 0.6180339887499. Пусть, например, мы работаем с байтами. Умножив золотое сечение на 28, получаем 158. Перемножим 8-битовый ключ и 158, получаем 16-битовое целое. Для таблицы длиной 25 в качестве хеширующего значения берем 5 младших битов младшего слова, содержащего такое произведение. Вот как можно реализовать этот метод:
- Аддитивный метод для строк переменной длины (размер таблицы равен 256). Для строк переменной длины вполне разумные результаты дает сложение по модулю 256. В этом случае результат hashValue заключен между 0 и 255.
- Исключающее ИЛИ для строк переменной длины (размер таблицы равен 256). Этот метод аналогичен аддитивному, но успешно различает схожие слова и анаграммы (аддитивный метод даст одно значение для XY и YX). Метод, как легко догадаться, заключается в том, что к элементам строки последовательно применяется операция "исключающее или". В нижеследующем алгоритме добавляется случайная компонента, чтобы еще улучшить результат.
- Исключающее ИЛИ для строк переменной длины (размер таблицы <= 65536). Если мы хешируем строку дважды, мы получим хеш-значение для таблицы любой длины до 65536. Когда строка хешируется во второй раз, к первому символу прибавляется 1. Получаемые два 8-битовых числа объединяются в одно 16-битовое.
typedef int HashIndexType;
HashIndexType Hash(int Key) {
return Key % HashTableSize;
}
Для успеха этого метода очень важен выбор подходящего значения hashTableSize.
Если, например, hashTableSize равняется двум, то для четных ключей
хеш-значения будут четными, для нечетных - нечетными. Ясно, что это нежелательно
- ведь если все ключи окажутся четными, они попадут в один элемент таблицы.
Аналогично, если все ключи окажутся четными, то hashTableSize, равное
степени двух, попросту возьмет часть битов Key в качестве индекса.
Чтобы получить более случайное распределение ключей, в качестве hashTableSize
нужно брать простое число, не слишком близкое к степени двух.
Пусть, например, размер таблицы hashTableSize равен 1024 (210). Тогда нам достаточен 16-битный индекс и S будет присвоено значение 16 - 10 = 6. В итоге получаем:/* 8-bit index */ typedef unsigned char HashIndexType; static const HashIndexType K = 158; /* 16-bit index */ typedef unsigned short int HashIndexType; static const HashIndexType K = 40503; /* 32-bit index */ typedef unsigned long int HashIndexType; static const HashIndexType K = 2654435769; /* w=bitwidth(HashIndexType), size of table=2**m */ static const int S = w - m; HashIndexType HashValue = (HashIndexType)(K * Key) >> S;
typedef unsigned short int HashIndexType;
HashIndexType Hash(int Key) {
static const HashIndexType K = 40503;
static const int S = 6;
return (HashIndexType)(K * Key) >> S;
}
typedef unsigned char HashIndexType;
HashIndexType Hash(char *str) {
HashIndexType h = 0;
while (*str) h += *str++;
return h;
}
typedef unsigned char HashIndexType;
unsigned char Rand8[256];
HashIndexType Hash(char *str) {
unsigned char h = 0;
while (*str) h = Rand8[h ^ *str++];
return h;
}
Здесь Rand8 - таблица из 256 восьмибитовых случайных чисел. Их точный
порядок не критичен. Корни этого метода лежат в криптографии; он оказался
вполне эффективным.
typedef unsigned short int HashIndexType;
unsigned char Rand8[256];
HashIndexType Hash(char *str) {
HashIndexType h;
unsigned char h1, h2;
if (*str == 0) return 0;
h1 = *str; h2 = *str + 1;
str++;
while (*str) {
h1 = Rand8[h1 ^ *str];
h2 = Rand8[h2 ^ *str];
str++;
}
/* h is in range 0..65535 */
h = ((HashIndexType)h1 << 8)|(HashIndexType)h2;
/* use division method to scale */
return h % HashTableSize
}
Размер хеш-таблицы должен быть достаточно большим, чтобы в ней оставалось
разумно большое число пустых мест. Как видно из таблицы 3.1, чем меньше
таблица, тем больше среднее время поиска ключа в ней. Хеш-таблицу можно
рассматривать как совокупность связанных списков. По мере того, как таблица
растет, увеличивается количество списков и, соответственно, среднее число
узлов в каждом списке уменьшается. Пусть количество элементов равно n.
Если размер таблицы равен 1, то таблица вырождается в один список длины
n. Если размер таблицы равен 2 и хеширование идеально, то нам придется
иметь дело с двумя списками по n/100 элементов в каждом. Это сильно
уменьшает длину списка, в котором нужно искать. Как мы видим в таблице
3.1, имеется значительная свободы в выборе длины таблицы.
| размер | время | размер | время | |
|---|---|---|---|---|
| 1 | 869 | 128 | 9 | |
| 2 | 432 | 256 | 6 | |
| 4 | 214 | 512 | 4 | |
| 8 | 106 | 1024 | 4 | |
| 16 | 54 | 2048 | 3 | |
| 32 | 28 | 4096 | 3 | |
| 64 | 15 | 8192 | 3 |
Реализация
В реализации алгоритма на Си операторы typedef T и compGT следует изменить так, чтобы они соответствовали данным, хранимым в массиве. Для работы программы следует также определить hashTableSize и отвести место под hashTable. В хеш-функции hash использован метод деления. Функция insertNode отводит память под новый узел и вставляет его в таблицу. Функция deleteNode удаляет узел и освобождает память, где он располагался. Функция findNode ищет в таблице заданный ключ.Метод закрытой адресации.
Только что рассматривалось хеширование со списками, но есть и другой вариант, когда используется массив определенной, превышающей количество данных, длины.Поэтому закрытые хеш-таблицы особенно эффективны, когда максимальные размеры входящего набора данных уже известены. Было доказано, что, когда закрытая таблица заполняется более чем на 50 процентов, ее эффективность значительно ухудшается (см. Структуры Данных, и Программируйте Проект на C, Робертом Крус, Брюсом Леунг, и Clovis Tondo, Prentice Холл, 1991).
Закрытые таблицы обычно используются для быстродействующего макетирования (они просты для программирования и быстры) и там, где быстрый доступ (нет связаного списока) приоритетен, а память легко доступна.
Пусть нам необходимо представлять множества элементов типа T, причем число элементов заведомо меньше n. Выберем некоторую функцию h, определенную на значениях типа T и принимающую значения 0..(n-1). Было бы хорошо, чтобы эта функция принимала на элементах будущего множества по возможности более разнообразные значения. Худший случай - это когда ее значения на всех элементах хранимого множества одинаковы. Эту функцию будем называть хеш-функцией.Введем два массива
val: array [0..n-1] of T;
used: array [0..n-1] of boolean;
(мы позволяем себе писать n-1 в качестве границы в определении
типа, хотя в паскале это не разрешается). В этих массивах будут
храниться элементы множества: оно равно множеству всех val [i]
для тех i, для которых used [i], причем все эти val [i] различ
ны. По возможности мы будем хранить элемент t на месте h(t),
считая это место "исконным" для элемента t. Однако может слу
читься так, что новый элемент, который мы хотим добавить, пре
тендует на уже занятое место (для которого used истинно). В этом
случае мы отыщем ближайшее справа свободное место и запишем эле
мент туда. ("Справа" значит "в сторону увеличения индексов";
дойдя до края, мы перескакиваем в начало.) По предположению,
число элементов всегда меньше n, так что пустые места гарантиро
ванно будут.Формально говоря, в любой момент должно соблюдаться такое требование: для любого элемента множества участок справа от его исконного места до его фактического места полностью заполнен.
Благодаря этому проверка принадлежности заданного элемента t осуществляется легко: встав на h(t), двигаемся направо, пока не дойдем до пустого места или до элемента t. В первом случае элемент t отсутствует в множестве, во втором присутствует. Если элемент отсутствует, то его можно добавить на найденное пустое место. Если присутствует, то можно его удалить (положив used = false).
Есть одна проблема:
>Дело в том, что при удалении требуемое свойство 'отсутствия пустот' может нарушиться. Поэтому будем делать так. Создав дыру, будем двигаться направо, пока не натолкнемся на еще одно пустое место (тогда на этом можно успокоиться) или на эле- мент, стоящий не на исконном месте. Во втором случае посмотрим, не нужно ли этот элемент поставить на место дыры. Если нет, то продолжаем поиск, если да, то затыкаем им старую дыру. При этом образуется новая дыра, с которой делаем все то же самое.
Здесь есть функции на Паскале, реализующие проверку принадлежности, добавление и удаление элементов в таких таблицах.
Для успешного функционирования желательно, чтобы данные занимали не более 80% всей таблицы.
Пример функции хеширования, используемой в Unix'ах:
/*--- HashPJW -----------------------------------------------------------*
(Адаптация PJW) обобщенного алгоритма хеширования Питера Веинбергер, *
Основанного на версии Аллена Холуб. Принимает указатель на *
элемент данных, который нужно проиндексировать и возвращает unsigned int *
---------------------------------------------------------------------------*/
#include <limits.h>
#define BITS_IN_int ( sizeof(int) * CHAR_BIT )
#define THREE_QUARTERS ((int) ((BITS_IN_int * 3) / 4))
#define ONE_EIGHTH ((int) (BITS_IN_int / 8))
#define HIGH_BITS ( ~((unsigned int)(~0) >> ONE_EIGHTH ))
unsigned int HashPJW
( const char * datum )
{
unsigned int hash_value, i;
for ( hash_value = 0; *datum; ++datum )
{
hash_value = ( hash_value << ONE_EIGHTH ) + *datum;
if (( i = hash_value & HIGH_BITS ) != 0 )
hash_value = (hash_value ^ (i >> THREE_QUARTERS)) & ~HIGH_BITS;
}
return ( hash_value );
}
 Вверх по странице, к оглавлению и навигации.
Вверх по странице, к оглавлению и навигации.