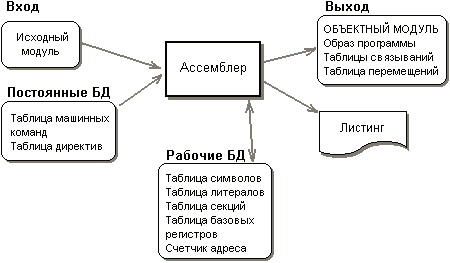
| Каталог | Индекс раздела |
| Назад | Оглавление | Вперед |
| Определение (не по ГОСТ) | Язык Ассемблера - система записи программы с детализацией до отдельной машинной команды, позволяющая использовать мнемоническое обозначение команд и символическое задание адресов. |
Поскольку в разных аппаратных архитектурах разные программно-доступные компоненты (система команд, регистры, способы адресации), язык Ассемблера аппаратно-зависимый. Программы, написанные на языке Ассемблера м.б. перенесены только на вычислительную систему той же архитектуры.
Программирование на языке Ассемблера позволяет в максимальной степени использовать особенности архитектуры вычислительной системы. До недавнего времени воспринималась как аксиома, что Ассемблерная программа всегда является более эффективной и в смысле быстродействия, и в смысле требований к памяти. Для Intel-архитектуры это и сейчас так. Но это уже не так для RISK-архитектур. Для того, чтобы программа могла эффективно выполняться в вычислительной среде с распараллеливанием на уровне команд, она д.б. определенным образом оптимизирована, т.е., команды д.б. расположены в определенном порядке, допускающим их параллельное выполнение. Программист просто не сможет покомандно оптимизировать всю свою программу. С задачей такой оптимизации более эффективно справляются компиляторы.
Доля программ, которые пишутся на языках Ассемблеров в мире, неуклонно уменьшается, прикладное программирование на языках Ассемблеров применяется только по недомыслию. Язык Ассемблера "в чистом виде" применяется только для написания отдельных небольших частей системного ПО: микроядра ОС, самых нижних уровней драйверов - тех частей, которые непосредственно взаимодействуют с реальными аппаратными компонентами. Этим занимается узкий круг программистов, работающих в фирмах, производящих аппаратуру и ОС. Зачем же нам тогда изучать построение Ассемблера?
Хотя разработка программ, взаимодействующих с реальными аппаратными компонентами, - редкая задача, в современном программировании при разработке прикладного, а еще более - промежуточного ПО довольно часто применяется технологии виртуальных машин. Для выполнения того или иного класса задач программно моделируется некоторое виртуальное вычислительное устройство, функции которого соответствуют нуждам этого класса задач. Для управления таким устройством для него м.б. создан соответствующий язык команд. (Широко известные примеры: MI AS/400, JVM.) Говоря шире, любую программу можно представить себе как виртуальное "железо", решающее конкретную задачу. (Конечный пользователь обычно не видит разницы между программой и аппаратурой и часто говорит не "мне программа выдала то-то", а "мне компьютер выдал то-то"). В некоторых случаях интерфейс программы м.б. удобно представить в виде системы команд, а следовательно, нужен соответствующий Ассемблер. (Это, конечно, относится не к программам "для чайников", а к инструментальным средствам программистов, системам моделирования и т.п.).
Предложения языка Ассемблера описывают команды или псевдокоманды (директивы). Предложения-команды задают машинные команды вычислительной системы; обработка Ассемблером команды приводит к генерации машинного кода. Обработка псевдокоманды не приводит к непосредственной генерации кода, псевдокоманда управляет работой самого Ассемблера. Для одной и той же аппаратной архитектуры м.б. построены разные Ассемблеры, в которых команды будут обязательно одинаковые, но псевдокоманды м.б. разные.
Во всех языках Ассемблеров каждое новое предложение языка начинается с новой строки. Каждое предложение, как правило, занимает одну строку, хотя обычно допускается продолжение на следующей строке/строках. Формат записи предложений языка м.б. жесткий или свободный. При записи в жестком формате составляющие предложения должны располагаться в фиксированных позициях строки. (Например: метка должна располагаться в позициях 1-8, позиция 9 - пустая, позиции 10-12 - мнемоника команды, позиция 13 - пустая, начиная с позиции 14 - операнды, позиция 72 - признак продолжения). Обычно для записи программ при жестком формате создаются бланки. Жесткий формат удобен для обработки Ассемблером (удобен и для чтения). Свободный формат допускает любое количество пробелов между составляющими предложения.
В общих случаях предложения языка Ассемблера состоят из следующих компонент:
Метка или имя является необязательным компонентом. Не во всех языках Ассемблеров эти понятия различаются. Если они различаются (например, MASM), то метка - точка программы, на которую передается управление, следовательно, метка стоит в предложении, содержащем команду; имя - имя переменной программы, ячейки памяти, следовательно, имя стоит в предложении, содержащем псевдокоманду резервирования памяти или определения константы. В некоторых случаях метка и имя могут отличаться даже синтаксически, так, в MASM/TASM после метки ставится двоеточие, а после имени - нет.
Однако, физический смысл и метки, и имени - одинаков, это - адрес памяти. Во всех случаях, когда Ассемблер встречает в программе имя или метку, он заменяет ее на адрес той ячейки памяти, к которую имя/метка именует. Правила формирования имен/меток совпадают с таковыми для языков программирования. В некоторых Ассемблерах (HLAM S/390) не делается различия между меткой и именем.
В языке должны предусматриваться некоторые специальные правила, позволяющие Ассемблеру распознать и выделить метку/имя, например:
Мнемоника - символическое обозначение команды/псевдокоманды.
Операнды - один или несколько операндов, обычно разделяемые запятыми. Операндами команд являются имена регистров, непосредственные операнды, адреса памяти (задаваемые в виде констант, литералов, символических имен или сложных выражений, включающих специальный синтаксис). Операнды псевдокоманд м.б. сложнее и разнообразнее.
Комментарии - любой текст, который игнорируется Ассемблером. Комментарии располагаются в конце предложения и отделяются от текста предложения, обрабатываемого Ассемблером, каким-либо специальным символом (в некоторых языках - пробелом). Всегда предусматривается возможность строк, содержащих только комментарий, обычно такие строки содержат специальный символ в 1-й позиции.
Константы - могут представлять непосредственные операнды или абсолютные адреса памяти. Применяются 10-ные, 8-ные, 16-ные, 2-ные, символьные константы.
Непосредственные операнды - записываются в сам код команды.
Имена - адреса ячеек памяти. При трансляции Ассемблер преобразует имена в адреса. Способ преобразования имени в значение зависит от принятых способов адресации. Как правило, в основным способом адресации в машинных языках является адресация относительная: адрес в команде задается в виде смещения относительно какого-то базового адреса, значение которого содержится в некотором базовом регистре. В качестве базового могут применяться либо специальные регистры (DS, CS в Intel) или регистры общего назначения (S/390).
Литералы - записанные в особой форме константы. Концептуально литералы - те же имена. При появлении в программе литерала Ассемблер выделяет ячейку памяти и записывает в нее заданную в литерале константу. Далее все появления этого литерала Ассемблер заменяет на обращения по адресу этой ячейки. Таким образом, литеральные константы, хранятся в памяти в одном экземпляре, независимо от числа обращений к ним.
Специальный синтаксис - явное описание способа адресации (например, указание базового регистра и смещения и т.п.).
Директивы являются указаниями Ассемблеру о том, как проводить ассемблирование. Директив м.б. великое множество. В 1-ом приближении мы рассмотрим лишь несколько практически обязательных директивы (мнемоники директив везде - условные, в конкретных Ассемблерах те же по смыслу директивы могут иметь другие мнемоники).
| Определение имени. Перед этой директивой обязательно стоит имя. Операнд этой директивы определяет значение имени. Операндом может быть и выражение, вычисляемое при ассемблировании. Имя может определяться и через другое имя, определенное выше. Как правило, не допускается определение имени со ссылкой вперед. | |
| Определение данных. Выделяются ячейки памяти и в них записываются значения, определяемые операндом директивы. Перед директивой может стоять метка/имя. Как правило, одной директивой могут определяться несколько объектов данных. В конкретных Ассемблерах может существовать либо одна общая директива DD, тогда тип данных, размещаемых в памяти определяется формой записи операндов, либо несколько подобных директив - для разных типов данных. В отличие от других,, эта директива приводит непосредственной к генерации некоторого выходного кода - значений данных. | |
| Резервирование памяти. Выделяются ячейки памяти, но значения в них не записываются. Объем выделяемой памяти определяется операндом директивы. Перед директивой может стоять метка/имя. | |
| END | Конец программного модуля. Указание Ассемблеру на прекращение трансляции. Обычно в модуле, являющемся главным (main) операндом этой директивы является имя точки, на которую передается управление при начале выполнения программы. Во всех других модулях эта директива употребляется без операндов. |
Ассемблер просматривает исходный программный модуль один или несколько раз. Наиболее распространенными являются двухпроходные Ассемблеры, выполняющие два просмотра исходного модуля. На первом проходе Ассемблер формирует таблицу символов модуля, а на втором - генерирует код программы
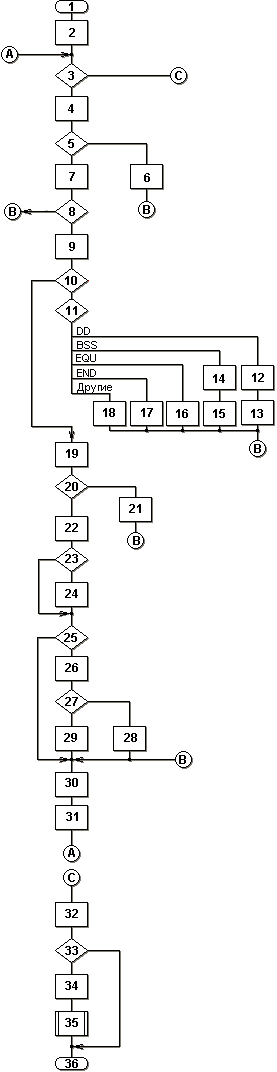
Алгоритм работы 1-го прохода двухпроходного Ассемблера показан на рисунке.
 |
|
Примечания
Таблица команд содержит одну строку для каждой мнемоники машинной команды. Ниже приведен пример структуры такой таблицы для простого случая, когда мнемоника однозначно определяет формат и длину команды. Обработка команд происходит по всего нескольким алгоритмам, зависящим от формата команды, поэтому в данном случае все параметры обработки могут быть представлены в виде данных, содержащихся в таблице.

Таблица директив содержит одну строку для каждой директивы Обработка каждой директивы происходит по индивидуальному алгоритму, поэтому параметры обработки нельзя представить в виде данных единого для всех директив формата. Для каждой директивы в таблице хранится только идентификация (имя или адрес, или номер) процедуры Ассемблера, выполняющей эту обработку. Некоторые директивы обрабатываются только на 1-ом проходе, некоторые - только на 2-ом, для некоторых обработка распределяется между двумя проходами.

Таблица символов является основным результатом 1-го прохода Ассемблера. Каждое имя, определенное в программе, должно быть записано в таблице символов. Для каждого имени в таблице хранится его значение. , размер объекта, связанного с этим именем и признак перемещаемости/неперемещаемости. Значением имени является число, в большинстве случаев интерпретируемое как адрес, поэтому разрядность значения равна разрядности адреса. Перемещаемость рассматривается в разделе, посвященном Загрузчикам, здесь укажем только, что значение перемещаемого имени должно изменяться при загрузке программы в память. Имена, относящиеся к командам или к памяти, выделяемой директивами DD, BSS, как правило, являются перемещаемыми (относительными), имена, значения которых определяются директивой EQU (см. ниже), являются неперемещаемыми (абсолютными).

Таблица литералов содержит запись для каждого употребленного в модуле литерала. Для каждого литерала в таблице содержится его символьное обозначение, длина и ссылка на значение. Литерал представляет собой константу, записанную в памяти. Обращение к литералам производится так же, как и к именам ячеек программы. По мере обнаружения в программе литералов Ассемблер заносит их данные в т.наз. литеральный пул. Значение, записываемое в таблицу литералов является смещением литерала в литеральном пуле. После окончания 1-го прохода Ассемблер размещает литеральный пул в конце программы (т.е., назначает ему адрес, соответствующий последнему значению счетчик адреса) и корректирует значения в таблице литералов, заменяя их смещениями относительно начала программы. После выполнения этой корректировки таблица литералов может быть совмещена с таблицей символов.

Структура таблиц Ассемблера выбирается таким образом, чтобы обеспечить максимальную скорость поиска в них.
Таблицы команд и директив являются постоянной базой данных. Они заполняются один раз - при разработке Ассемблера, а затем остаются неизменными. Эти таблицы целесоообразно строить как таблицы прямого доступа с функцией хеширования, осуществляющей преобразование мнемоники в адрес записи в таблице. Имеет смысл постараться и подобрать функцию хеширования такой, чтобы в таблице не было коллизий. Поскольку заполнение таблицы происходит один раз, а доступ к ней производится многократно, эти затраты окупаются.
Таблица символов формируется динамически - в процессе работы 1-го прохода. Поиск же в этой таблице осуществляется как в 1-ом проходе (перед занесением в таблицу нового имени, проверяется, нет ли его уже в таблице). Построение этой таблицы как таблицы прямого доступа не очень целесообразно, так как неизбежно возникновение коллизий. Поэтому поиск в таблице символов может быть дихотомическим, но для этого таблица должна быть упорядочена. Поскольку новые имена добавляются в таблицу "по одному", и после каждого добавления упорядоченность таблицы должна восстанавливаться, целесообразно применять алгоритму сортировки, чувствительные к исходной упорядоченности данных.
Эти же соображения относятся и к другим таблицам, формируемым Ассемблером в процессе работы. При больших размерах таблиц и размещении их на внешней памяти могут применяться и более сложные (но и более эффективные) методы их организации, например - B+-деревья.
Обычно 2-й проход Ассемблера читает исходный модуль с самого начала и отчасти повторяет действия 1-го прохода (лексический разбор, распознавание команд и директив, подсчет адресов). Это, однако, скорее дань традиции - с тех времен, когда в вычислительных системах ощущалась нехватка (или даже полное отсутствие) внешней памяти. В те далекие времена колода перфокарт или рулон перфоленты, содержащие текст модуля, вставлялись в устройство ввода повторно. В системах с эволюционным развитием сохраняются перфокарты и перфоленты (виртуальные), так что схема работы Ассемблера - та же. В новых системах Ассемблер может создавать промежуточный файл - результат 1-го прохода, который является входом для 2-го прохода. Каждому оператору исходного модуля соответствует одна запись промежуточного файла, и формат этой записи приблизительно такой:

Текст исходного оператора нужен только для печати листинга, Ассемблер на 2-ом проходе использует только первые 4 поля записи. Первое поле позволяет исключить строки, целиком состоящие из комментария. Второе поле позволяет избежать подсчета адресов, третье - поиска мнемоники в таблицах. Основная работа 2-го прохода состоит в разборе поля операндов и генерации объектного кода.
Некоторые общие соображения, касающиеся этой работы. Объектный код команды состоит из поля кода операции и одного или нескольких полей операндов. Код операции, как правило, имеет размер 1 байт, количество, формат и семантика полей операндом определяется для каждого типа команд данной аппаратной платформы. В общем случае операндом команды может быть:
Виды адресных выражений зависят от способов адресации вычислительной системы, некоторые (возможно, наиболее типовые) способы адресации:
Адресное выражение моет содержать арифметические операции, соображения, касающиеся арифметики в этом случае - те же, что и в адресной арифметике языка C.
Имена в адресных выражениях должны заменяться на значения. Замена абсолютных имен (определенных в директиве EQU) очень проста - значение имени из таблицы символов просто подставляется вместо имени. Перемещаемые имена (метки и имена переменных) превращаются Ассемблером в адресное выражение вида [базовый регистр]+смещение. В таблице символов значения этих имен определены как смещение соответствующих ячеек памяти относительно начала программы. При трансляции имен необходимо, чтобы:
Первые два требования обеспечиваются директивами, третье - машинными командами. Ответственность за то, чтобы при обеспечении этих требований директивы согласовывались с командами, лежит на программисте. Эти требования по-разному реализуются в разных вычислительных системах. Приведем два примера.
В Intel Ассемблер использует в качестве базовых сегментные регистры (DS при трансляции имен переменных, CS при трансляции меток). Для простой программы, состоящей из одной секции, Загрузчик перед выполнением заносит во все сегментные регистры сегментный адрес начала программы и Ассемблер считает все смещения относительно него. Сложная программа может состоять из нескольких секций, и в сегментном регистре может содержаться адрес той или иной секции, причем содержимое сегментного регистра может меняться в ходе выполнения программы. Загрузка в сегментный регистр адреса секции выполняется машинными командами:
MOV AX,секция
MOV сегментный_регистр,AX
Для того, чтобы Ассемблер знал, что адрес секции находится в сегментном_регистре, применяется директива:
ASSUME сегментный_регистр:секция
Далее при трансляции имен Ассемблер превращает имена в адресные выражения вида
[сегментный_регистр]+смещение в секции
Отмена использования сегментного регистра задается директивой:
ASSUME сегментный_регистр:NOTHING
Обратим внимание на то, что при трансляции команды
MOV AX,секция
в поле операнда заносится относительный адрес секции, при выполнении же здесь должен быть ее абсолютный адрес. Поэтому поля операндов такого типа должны быть модифицированы Загрузчиком после размещения программы в оперативной памяти.
Более гибкая система базовой адресации применяется в S/360, S/370, S/390. В качестве базового может быть использован любой регистр общего назначения. Директива:
USING относительный_адрес,регистр
сообщает Ассемблеру, что он может использовать регистр в качестве базового, и в регистре содержится адрес - 1-й операнд. Чаще всего относительный_адрес кодируется как *
(обозначение текущего значения счетчика адреса), это означает, что в регистре содержится адрес первой команды, следующей за директивой USING. Занесение адреса в базовый регистр выполняется машинной командой BALR. Обычный контекст определения базового регистра:
BALR регистр,0
USING *,регистр
С такими операндами команда BALR заносит в регистр адрес следующей за собой команды.
Зная смещение именованной ячейки относительно начала программы и смещение относительно начала же программы содержимого базового регистра, Ассемблер легко может вычислить смещение именованной ячейки относительно содержимого базового регистра.
В отличие от предыдущего примера, в этом случае не требуется модификации при загрузке, так как команда BALR заносит в регистр абсолютный адрес.
Директива
DROP регистр
отменяет использование регистра в качестве базового.
В качестве базовых могут быть назначены несколько регистров, Ассемблер сам выбирает, какой из них использовать в каждом случае.
Выше мы говорили, что Ассемблер "знает" базовый регистр и его содержимое. Это "знание хранится в таблице базовых регистров. Обычно таблица содержит строки для всех регистров, которые могут быть базовыми и признак, используется ли регистр в таком качестве. Формат строки таблицы:

Алгоритм выполнения 2-го прохода представлен на рисунке. Мы исходили из того, что 2-й проход использует промежуточный файл, сформированный 1-ым проходом. Если же 2-й проход использует исходный модуль, то алгоритм должен быть расширен лексическим разбором оператора, распознаванием мнемоники и подсчетом адресов - так же, как и в 1-ом проходе.
 |
|
При рассмотрении алгоритма мы принимали во внимание только генерацию объектных кодов, соответствующих командам и константам. Мы не рассматривали то, какова общая структура объектного модуля. Эти вопросы будут рассматриваться в Теме 4.
| OGR |
Установка адреса. Операндом директивы является числовая константа или выражение, вычисляемое при ассемблировании. Как правило, Ассемблер считает, что первая ячейка обрабатываемой им программы располагается по адресу 0. Директива ORG устанавливает счетчик адресов программы в значение, определяемое операндом. Так, при создании COM-программ для MS DOS программа начинается с директивы ORG 100H. Этим оператором резервируется 256 байт в начале программы для размещения префикса программного сегмента. В абсолютных программах директива применяется для размещения программы по абсолютным адресам памяти. |
| START/ SECT |
Начало модуля или программной секции. Операндом директивы является имя секции. Этой директивой устанавливается в 0 счетчик адресов программы.
Программа может состоять из нескольких программных секций, в каждой секции счет адресов ведется от 0. При обработке этой директивы на 1-ом проходе Ассемблер создает таблицу программных секций вида:
На 1-ом проходе Ассемблер составляет список секций, и только в конце 1-го прохода определяет их длины и относительные адреса в программе. |
| Директивы связывания | |
| ENT | Входная точка. Операндом этой директивы является список имен входных точек программного модуля - тех точек, на которые может передаваться управление извне модуля или тех данных, к которым могут быть обращения извне. |
| EXT | Внешняя точка. Операндом этой директивы является список имен, к которым есть обращение в модуле, но сами эти имена определены в других модулях. |
| Эти директивы обрабатываются на 2-ом проходе, и на их основе строятся таблицы связываний и перемещений (см. Тему 4). | |
Мы показали, что в двухпроходном Ассемблере на 1-ом проходе осуществляется определение имен, а на втором - генерация кода.
Можно ли построить однопроходный Ассемблер? Трудность состоит в том, что в программе имя может появиться в поле операнда команды прежде, чем это имя появится в поле метки/имени, и Ассемблер не может преобразовать это имя в адресное выражение, т.к. еще на знает его значение. Как решить эту проблему?
Для чего может понадобиться многопроходный Ассемблер? Единственная необходимость во многих проходах может возникнуть, если в директиве EQU разрешены ссылки вперед. Мы упоминали выше, что имя в директиве EQU может определяться через другое имя. В одно- или двухпроходном Ассемблере это другое имя должно быть обязательно определено в программе выше. В многопроходном Ассемблере оно может быть определено и ниже. На первом проходе происходит определение имен и составление таблицы символов, но некоторые имена остаются неопределенными. На втором проходе определяются имена, не определившиеся во время предыдущего прохода. Второй проход повторяется до тех пор, пока не будут определены все имена (или не выяснится, что какие-то имена определить невозможно). На последнем проходе генерируется объектный код.
| Назад | Оглавление | Вперед |
| Каталог | Индекс раздела |