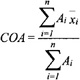|
|
|
|||
        |
|
|
|
[an error occurred while processing this directive]
Figure 1.4 shows fuzzy membership functions that can be used to describe the variable x. There are Gaussian representations for each of the five fuzzy terms used to describe x: VERY SMALL, SMALL, MEDIUM, LARGE, and VERY LARGE. Notice that for any value of x, the degree of membership, μ, for more than one term can be non-zero. The degree of membership can be thought of as the extent to which x is accurately represented by the term in question. If, for example, x is such that μVERY SMALL = 0.00, then the interpretation is that the value of x is not described by the term VERY SMALL; it is not very small to any degree. If, on the other hand, x is such that μVERY SMALL = 1.00, then the interpretation is that the value of x is exactly described by the term VERY SMALL. As an example, consider the situation in which x = 0.75. In this instance, the membership function values for the various fuzzy terms are: μVERY SMALL = 0.24, μSMALL = 0.62, μMEDIUM = μLARGE = μVERY LARGE = 0.0. Thus, the variable value x = 0.75 has been fuzzified with the determination of the membership function values.
Notice in Figure 1.4 that as x changes, so too do the values of the membership functions. Consider, for instance, what happens to the membership function values as x increases from 0.0 to 5.0. When x has a value of 0.0, then μVERY SMALL = 1.00 and all other membership functions are 0.00. As x is gradually increased, the value of μVERY SMALL decreases and the value of μSMALL begins to increase (all other membership function values remain 0.00 at this point). We can think of this situation in the following way: as x is increasing, our confidence that x is VERY SMALL (or the extent to which we feel that value of x is accurately described by the term VERY SMALL) is waning. On the other hand, we feel that x is now to some extent described by the term SMALL. As x continues to grow, its membership in the set VERY SMALL goes down; its membership in the set SMALL goes up. With this representation, we do not have to decide that one single point at which x goes from being VERY SMALL to being SMALL. There is a continuous representation or mapping from discrete values to fuzzy sets, and yes, the sets overlap. We are no longer limited by conventional set theory in which “ball belongs to the set of red balls or the set of blue balls.” Thank goodness, because in our world, there are definitely balls that are neither purely red nor purely blue, rather they are usually some shade of purple. Now that x has been fuzzified, simply go to the rule set and implement the rule that is applicable. But wait one minute, more than one rule is applicable for a particular value of x. In fact, all of the rules that have nonzero membership function values are applicable to some extent, and this marks a major difference between traditional expert systems and fuzzy systems: in fuzzy systems more than one rule can be applied and there is no conflict between rules. In our particular example, rules 3–5 on page 7 really do not apply since x is not MEDIUM, nor is it LARGE, nor is it VERY LARGE (the membership function values for these sets is 0.00). Thus, these rules are thought of as being applicable to the degree zero. Rules 1 and 2, however, are characterized by fuzzy sets that have non-zero degrees of membership. The approach used to apply both rules in fuzzy systems is to take a weighted average of the value of f(x) prescribed by all applicable rules. Thus, the value of f(x) prescribed by rule 1 will be implemented to the degree 0.24, while the value of f(x) prescribed by rule 2 will be implemented to the degree 0.62. The attempt to carry out the instructions of the previous paragraph, namely to implement the value of f(x) prescribed by the two applicable rules, i.e., to take a weighted average of the two rules, can bring to light another slight problem: How does one find the value of f(x) for BIG and MEDIUM, the values prescribed by the two applicable rules? To get values for the weighted average, membership functions are needed for the output variable f(x). Such membership functions are shown in Figure 1.5. Here, three membership function values are provided, although any number of membership functions could have been used.
With the above membership functions defined, the process of taking the weighted average of the values of f(x) prescribed by the applicable rules can be thought of in graphical terms. What is done is to re-draw the membership functions associated with BIG and MEDIUM. However, the membership function forms are reduced or diminished according to the degree of membership associated with the particular rule. This process is depicted in Figure 1.6. BIG is reduced by cutting the function off at a height equal to the minimum value of μ associated with the condition side of the rule prescribing this action. In this particular instance, BIG is cut off at a height of 0.24 instead of the height of being drawn to a height of 1.00 as shown in Figure 1.5. MEDIUM is scaled with a height of 0.62. Now, the final crisp value of f(x) obtained for the given value of x = 0.75 is obtained by calculating the center of area (COA) of the two scaled-down membership functions as shown in Figure 1.6. The center of area is computed using the formula:
where n is the number of rules, Ai is the area of the ith membership function describing f(x) for the ith rule, and xi is the center of area for the membership function describing f(x) for the ith rule. The center of area for this instance provides the value of f(x) = 2.28; this is the final crisp value prescribed by the input x = 0.75. This center of area method is commonly used in fuzzy systems because of its simplicity. However, there are more involved defuzzification schemes and some will be used in later chapters of this book. But, in general, each method of defuzzification provides the controller with a mechanism for returning crisp (numerical) output values (f(x)).
Copyright © CRC Press LLC
|
 |
         |
|
)
)