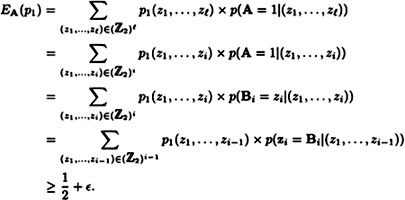|
|
|
|||
        |
|
|
|
[an error occurred while processing this directive]
The relevance to PRBGs is as follows. Consider the sequence of Now, consider sequences produced by the PRBG. Suppose a k-bit seed is chosen at random, and then the PRBG is used to obtain a bit-string of length Even though the two probability distributions p0 and p1 may be quite different, it is still conceivable that they might be ε-distinguishable only for small values of ε. This is our objective in constructing PRBGs. Example 12.3 Suppose that a PRBG only produces sequences in which exactly
In this case, the algorithm A is deterministic. It is not hard to see that
and
It can be shown that
Hence, for any fixed value of ε < 1, p0 and p1 are ε-distinguishable if 12.2.1 Next Bit PredictorsAnother useful concept in studying PRBGs is that of a next bit predictor, which works as follows. Let f be a We can give a more precise formulation of this concept in terms of probability distributions, as follows. We have already defined the probability distribution p1 on In view of these definitions, we have the following characterization of a next bit predictor. THEOREM 12.1 Let f be a
PROOF The probability of correctly predicting the ith bit is computed by summing over all possible (i - 1)-tuples (z1, … , zi-1) the product of the probability that the (i - 1)-tuple, (z1,…, zi-1) is produced by the PRBG and the probability that the ith bit is predicted correctly given the (i - 1)-tuple, (z1, … , zi-1). The reason for the expression 1/2 + ε in this definition is that any predicting algorithm can predict the next bit of a random sequence with probability 1/2. If a sequence is not random, then it may be possible to predict the next bit with higher probability. (Note that it is unnecessary to consider algorithms that predict the next bit with probability less than 1/2, because in this case an algorithm that replaces every prediction z by 1 - z will predict the next bit with probability greater than 1/2.) We illustrate these ideas by producing a next-bit predictor for the Linear Congruential Generator of Example 12.1. Example 12.1 (Cont.) For any i such that 1 ≤ i ≤ 9, Define Bi(z) = 1 - z. That is, Bi predicts that a 0 is most likely to be followed by a 1, and vice versa. It is not hard to compute from Table 12.1 that each of these predictors Bi is a We can use a next bit predictor to construct a distinguishing algorithm A, as shown in Figure 12.3. The input to algorithm A is a sequence of bits,
THEOREM 12.2 Suppose Bi is an ε-next bit predictor for the PROOF First, observe that
Also, the output of A is independent of the values of
Copyright © CRC Press LLC
|
 |
         |
|
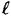 bits produced by the PRBG. There are
bits produced by the PRBG. There are 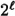 possible sequences, and if the bits were chosen independently at random, each of these
possible sequences, and if the bits were chosen independently at random, each of these 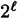 sequences would occur with equal probability
sequences would occur with equal probability 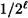 . Thus a truly random sequence corresponds to an equiprobable distribution on the set of all bit-strings of length
. Thus a truly random sequence corresponds to an equiprobable distribution on the set of all bit-strings of length 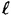 . Suppose we denote this probability distribution by p0.
. Suppose we denote this probability distribution by p0.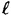 . Then we obtain a probability distribution on the set of all bit-strings of length
. Then we obtain a probability distribution on the set of all bit-strings of length 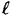 , which we denote by p1. (For the purposes of illustration, suppose we make the simplifying assumption that no two seeds give rise to the same sequence of bits. Then, of the
, which we denote by p1. (For the purposes of illustration, suppose we make the simplifying assumption that no two seeds give rise to the same sequence of bits. Then, of the 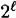 possible sequences, 2k sequences each occur with probability 1/2k, and the remaining
possible sequences, 2k sequences each occur with probability 1/2k, and the remaining 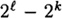 sequences never occur. So, in this case, the probability distribution p1 is very non-uniform.)
sequences never occur. So, in this case, the probability distribution p1 is very non-uniform.)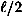 bits have the value 0 and
bits have the value 0 and 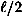 bits have the value 1. Define the function A by
bits have the value 1. Define the function A by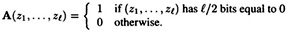
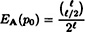
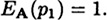
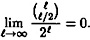
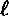 is sufficiently large.
is sufficiently large.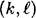 -PRBG. Suppose we have a probabilistic algorithm Bi, which takes as input the first i-1 bits produced by f (given an unknown seed), say z1, …, zi-1, and attempts to predict the next bit zi. The value i can be any value such that
-PRBG. Suppose we have a probabilistic algorithm Bi, which takes as input the first i-1 bits produced by f (given an unknown seed), say z1, …, zi-1, and attempts to predict the next bit zi. The value i can be any value such that 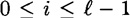 . We say that Bi is an ε-next bit predictor if Bi can predict the ith bit of a pseudo-random sequence with probability at least 1/2 + ε, where ε > 0.
. We say that Bi is an ε-next bit predictor if Bi can predict the ith bit of a pseudo-random sequence with probability at least 1/2 + ε, where ε > 0.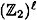 induced by the PRBG f. We can also look at the probability distributions induced by f on any of the
induced by the PRBG f. We can also look at the probability distributions induced by f on any of the 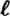 pseudo-random output bits (or indeed on any subset of these
pseudo-random output bits (or indeed on any subset of these 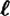 output bits). So, for
output bits). So, for 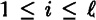 , we will can think of the ith pseudo-random output bit as a random variable that we will denote by zi.
, we will can think of the ith pseudo-random output bit as a random variable that we will denote by zi.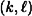 -PRBG. Then the probabilistic algorithm Bi is an ε-next bit predictor for f if and only if
-PRBG. Then the probabilistic algorithm Bi is an ε-next bit predictor for f if and only if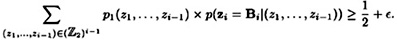
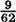 -next bit predictor (i.e., they predict the next bit correctly with probability 20/31).
-next bit predictor (i.e., they predict the next bit correctly with probability 20/31). , and A calls the algorithm Bi as a subroutine.
, and A calls the algorithm Bi as a subroutine.)
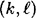 -PRBG f. Let p1 be the probability distribution induced on
-PRBG f. Let p1 be the probability distribution induced on 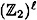 by f, and let p0 be the uniform probability distribution on
by f, and let p0 be the uniform probability distribution on 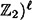 . Then A, as described in Figure 12.3, is an ε-distinguisher of p1 and p0.
. Then A, as described in Figure 12.3, is an ε-distinguisher of p1 and p0.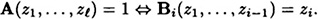
 . Thus we can compute as follows:
. Thus we can compute as follows: