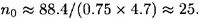|
|
|
|||
        |
|
|
|
[an error occurred while processing this directive]
DEFINITION 2.6 Suppose L is a natural language. The entropy of L is defined to be the quantity
and the redundancy of L is defined to be
REMARK HL measures the entropy letter of the language L. A random language would have entropy log2 In the case of the English language, a tabulation of a large number of digrams and their frequencies would produce an estimate for H(P2). empirical result that 1.0 ≤ HL ≤ 1.5. That is, the average information content in English is something like one to one and a half bits per letter! Using 1.25 as our estimate of HL gives a redundancy of about 0.75. This means that the English language is 75% redundant! (This is not to say that one can arbitrarily remove three out of every four letters from English text and hope to still be able to read it. What it does mean is that it is possible to find a Huffman encoding of n-grams, for a large enough value of n, which will compress English text to about one quarter of its original length.) Given probability distributions on Given y ∈ Cn, define
That is, K(y) is the set of keys K for which y is the encryption of a meaningful string of plaintext of length n, i.e., the set of “possible” keys, given that y is the ciphertext. If y is the observed sequence of ciphertext, then the number of spurious keys is |K(y)| - 1, since only one of the “possible” keys is the correct key. The average number of spurious keys (over all possible ciphertext strings of length n) is denoted by
From Theorem 2.10, we have that
Also, we can use the estimate
provided n is reasonably large. Certainly,
Then, if
Next, we relate the quantity H(K|Cn) to the number of spurious keys,
where we apply Jensen’s Inequality (Theorem 2.5) with f(x) = log2 x. Thus we obtain the inequality
Combining the two inequalities (2.1) and (2.2), we get that
In the case where keys are chosen equiprobably (which maximizes H(K)), we have the following result. THEOREM 2.11 Suppose
The quantity We have one more concept to define. DEFINITION 2.7 The unicity distance of a cryptosystem is defined to be the value of n, denoted by n0, at which the expected number of spurious keys becomes zero; i.e., the average amount of ciphertext required for an opponent to be able to uniquely compute the key, given enough computing time. If we set
As an example, consider the Substitution Cipher. In this cryptosystem,
This suggests that, given a ciphertext string of length at least 25, (usually) a unique decryption is possible.
Copyright © CRC Press LLC
|
 |
         |
|
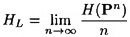
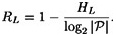
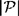 . So the quantity RL measures the fraction of “excess characters,” which we think of as redundancy.
. So the quantity RL measures the fraction of “excess characters,” which we think of as redundancy.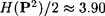 is one estimate obtained in this way. One could continue, tabulating trigrams, etc. and thus obtain an estimate for HL. In fact, various experiments have yielded the
is one estimate obtained in this way. One could continue, tabulating trigrams, etc. and thus obtain an estimate for HL. In fact, various experiments have yielded the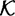 and
and 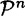 , we can define the induced probability distribution on
, we can define the induced probability distribution on 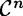 , the set of n-grams of ciphertext (we already did this in the case n = 1). We have defined Pn to be a random variable representing an n-gram of plaintext. Similarly, define Cn to be a random variable representing an n-gram of ciphertext.
, the set of n-grams of ciphertext (we already did this in the case n = 1). We have defined Pn to be a random variable representing an n-gram of plaintext. Similarly, define Cn to be a random variable representing an n-gram of ciphertext.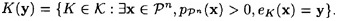
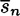 . Its value is computed to be
. Its value is computed to be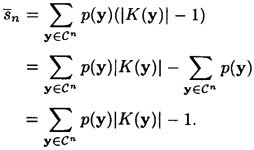
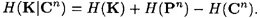
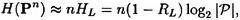
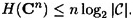
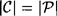 , it follows that
, it follows that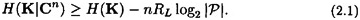
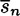 . We compute as follows:
. We compute as follows: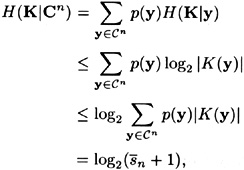
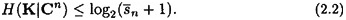
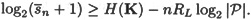
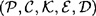 is a cryptosystem where
is a cryptosystem where 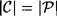 and keys are chosen equiprobably. Let RL denote the redundancy of the underlying language. Then given a string of ciphertext of length n, where n is sufficiently large, the expected number of spurious keys,
and keys are chosen equiprobably. Let RL denote the redundancy of the underlying language. Then given a string of ciphertext of length n, where n is sufficiently large, the expected number of spurious keys, 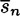 , satisfies
, satisfies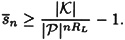
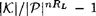 approaches 0 exponentially quickly as n increases. Also, note that the estimate may not be accurate for small values of n, especially since H(Pn)/n may not be a good estimate for HL if n is small.
approaches 0 exponentially quickly as n increases. Also, note that the estimate may not be accurate for small values of n, especially since H(Pn)/n may not be a good estimate for HL if n is small.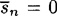 in Theorem 2.11 and solve for n, we get an estimate for the unicity distance, namely
in Theorem 2.11 and solve for n, we get an estimate for the unicity distance, namely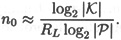
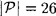 and
and 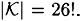 !. If we take RL = 0.75, then we get an estimate for the unicity distance of
!. If we take RL = 0.75, then we get an estimate for the unicity distance of