 |
Figure 1: Program with shared libraries Picture of executable, shared libraries main excutable, app library, C library files from different places arrows show refs from main to app, main to C, app to C |
| Program libraries date back to the earliest days of computing, since
programmers quickly realized that they could save a lot of time and effort
by reusing chunks of program code. With the advent of compilers for
languages like Fortran and COBOL, libraries became an integral part of
programming. Compiled languages use libraries explictly when a program
calls a standard procedure such as sqrt(), and they use libraries
implicitly for I/O, conversions, sorting, and many other functions too
complex to express as in-line code. As languages have gotten more complex,
libraries have gotten correspondingly more complex. When I wrote a Fortran
77 compiler twenty years ago, the runtime library was already more work
than the compiler itself, and a Fortran 77 library is far simpler than one
for C++.
The growth of language libraries means not only that all programs include library code, but that most programs include a lot of the same library code. Every C program, for example, uses the system call library, nearly all use the standard I/O library routines such as printf, and many use other popular libraries for math, networking, and other common functions. This means that in a typical Unix system with a thousand compiled programs, there's close to a thousand copies of printf. If all those programs could share a single copy of the library routines they use, the savings in disk space would be substantial. (On a Unix system without shared libraries, there's five to ten megabytes of copies of printf alone.) Even more important, if running programs could share a single in-memory copy of the libraries, the main memory savings could be very significant, both saving memory and improving paging behavior.
All shared library schemes work essentially the same way. At link time, the linker searches through libraries as usual to find modules that resolve otherwise undefined external symbols. But rather than copying the contents of the module into the output file, the linker makes a note of what library the module came from, and puts a list of the libraries in the executable. When the program is loaded, startup code finds those libraries and maps them into the program's address space before the program starts, Figure 1. Standard operating system file mapping semantics automatically share pages that are mapped read-only or copy-on-write. The startup code that does the mapping may be in the operating system, the executable, in a special dynamic linker mapped into the process' address space, or some combination of the three. |
| |
Figure 1: Program with shared libraries Picture of executable, shared libraries main excutable, app library, C library files from different places arrows show refs from main to app, main to C, app to C |
In this chapter, we look at static linked shared libraries, that is, libraries where program and data addresses in libraries are bound to executables at link time. In the next chapter we look at the considerably more complex dynamic linked libraries. Although dynamic linking is more flexible and more "modern", it's also a lot slower than static linking because a great deal of work that would otherwise have been done once at link time is redone each time a dynamically linked program starts. Also, dynamically linked programs usually use extra ``glue'' code to call routines in shared libraries. The glue usually contains several jumps, which can slow down calls considerably. On systems that support both static and dynamic shared libraries, unless programs need the extra flexibility of dynamic linking, they're faster and smaller with static linked libraries.
A much more interesting problem occurs when the library is present, but the library has changed since the program was linked. In a conventionally linked program, symbols are bound to addresses and library code is bound to the executable at link time, so the library the program was linked with is the one it uses regardless of subsequent changes to the library.. With static shared libraries, symbols are still bound to addresses at link time, but library code isn't bound to the executable until run time. (With dynamic shared libraries, they're both delayed until runtime.)
A static linked share library can't change very much without breaking the programs that it is bound to. Since the addresses of routines and data in the library are bound into the program, any changes in the addresses to which the program is bound will cause havoc.
A static shared library can sometimes be updated without breaking the programs that use it, if the updates can be made in a way that don't move any addresses in the library that programs depend on. This permits "minor version" updates, typically for small bug fixes. Larger changes unavoidably change program addresses, which means that a system either needs multiple versions of the library, or forces programmers to relink all their programs each time the library changes. In practice, the solution is invariably multiple versions, since disk space is cheap and tracking down every executable that might have used a shared library is rarely possible.
There's invariably a master table of shared library address space on each system, with libraries starting some place in the address space far away from applications. Linux's start at hex 60000000, BSD/OS at a0000000. Commercial vendors subdivide the address space further between vendor supplied libraries and user and third-party libraries which start at a0800000 in BSD/OS, for example.
Generally both the code and data addresses for each library are explicitly defined, with the data area starting on a page boundary a page or two after the end of the code. This makes it possible to create minor version updates, since the updates frequently don't change the data layout, but just add or change code.
Each individual shared library exports symbols, both code and data, and usually also imports symbols if the library depends on other libraries. Although it would work if one just linked routines together into a shared library in haphazard order, real libraries use some discipline in assigning addresses to make it easier, or at least possible, to update a library without changing the addresses of exported symbols. For code addresses, rather than exporting the actual address of each routine, the library contains a table of jump instructions which jump to all of the routines, with the addresses of the jump instructions exported as the addresses of the routines. All jump instruction are the same size, so the addresses in the jump table are easy to compute and won't change from version to version so long as no entries are added or deleted in the middle of the table. One extra jump per routine is an insignificant slowdown, but since the actual routine addresses are not visible, new versions of the library will be compatible even if routines in the new version aren't all the same sizes and addresses as in the old version.
For exported data, the situation is more difficult, since there's no easy way to add a level of indirection like the one for code addresses. In practice it turns out that exported data tends to be tables of known sizes that change rarely, such as the array of FILE structures for the C standard I/O library or single word values like errno (the error code from the most recent system call) or tzname (pointers to two strings giving the name of the current time zone.) With some manual effort, the programmer who creates the shared library can collect the exported data at the front of the data section in front of any anonymous data that are part of individual routines, making it less likely that exported addresses will change from one version to the next.
| Figure 2: Structure of typical shared library File header, a.out, COFF, or ELF header (Initialization routine, not always present) Jump table Code Global data Private data |
Some shared libraries start with a small bootstrap routine used to map in the rest of the library. After that comes the jump table, aligned on a page boundary if it's not the first thing in the library. The exported address of each public routine in the library is the jump table entry. Following the jump table is the rest of the text section (the jump table is considered to be text, since it's executable code), then the exported data and private data. The bss segment logically follows the data, but as in any other executable file, isn't actually present in the file.
Creating the shared library involves these basic steps, which we discuss in greater detail below:
A minor complication occurs on architectures like the x86 that have different sizes of jump instructions. For libraries containing less than 64K of code, short 3 byte jumps are adequate. For libraries larger than that, longer 5 byte jumps are necessary. Mixed sizes of jumps aren't very satisfactory, both because it makes the table addresses harder to compute and because it makes it far harder to make the jump table compatible in future builds of the library. The simplest solution is to make all of the jumps the largest size. Alternatively, make all of the jumps short, and for routines that are too far away for short jumps, generate anonymous long jump instructions at the end of the table to which short instructions can jump. (That's usually more trouble than it's worth, since jump tables are rarely more than a few hundred entries in the first place.)
| Figure 3: Jump table
|
One minor complication involves interlibrary references. If you're creating, say, a shared math library that uses routines from the shared C library, the references have to be made correctly. Assuming that the library whose routines are needed has already been built when the linker builds the new library, it needs only to search the old library's stub library, just like any normal executable that refers to the old library. This will get all of the references correct. The only remaining issue is that there needs to be some way to ensure that any programs that use the new library also link to the old library. Suitable design of the new stub library can ensure that.
The data global symbols are wherever the linker put them in the shared library image, and the most reasonable way to get their values is to create the shared library with a symbol table and extract the symbols from that symbol table. For code global symbols, the entry points are all in the jump table, so it's equally easy to extract the symbols from the shared library or compute the addresses from the base address of the jump table and each symbol's position in the table.
Unlike a normal library module, a module in the stub library contains no code nor data, but just has symbol definitions. The symbols have to be defined as absolute numbers rather than relocatable, since the shared library has already had all of its relocation done. The library creation program extracts each routine from the input library, and from that routine gets the defined and undefined globals, as well as the type (text or data) of each global. It then writes the stub routine, usually as a little assembler program, defining each text global as the address of the jump table entry, each data or bss global as the actual address in the shared library, and each undefined global as undefined. When it has a complete set of stub sources, it assembles them all and combines them into a normal library archive.
COFF stub libraries use a different, more primitive design. They're single object files with two named sections. The .lib section contains all of the relocation information pointing at the shared library, and the .init section contains initialization code that is linked into each client program, typically to initialize variables in the shared library.
Linux shared libraries are simpler still, an a.out file containing the symbol definitions with "set vector" symbols described in more detail below for use at program link time.
Shared libraries have names assigned that are mechanically derived from the original library, adding a version number. If the original library was called /lib/libc.a, the usual name for the C library, and the current library version is 4.0, the stub library might be /lib/libc_s.4.0.0.a and the shared library image /shlib/libc_s.4.0.0. (The extra zero allows for minor version updates.) Once the libraries are moved into the appropriate directories they're ready to use.
The first number changes each time a new incompatible version of the library is released. A program linked with a 4.x.x library can't use a 3.x.x nor a 5.x.x. The second number is the minor version. On Sun systems, each executable requires a minor version at least as great as the one with which the executable was linked. If it were linked with 4.2.x, for example, it would run with a 4.3.x library but not a 4.1.x. Other systems treat the second component as an extension of the the first component, so an executable linked with a 4.2.x library will only run with a 4.2.x library. The third component is universally treated as a patch level. Executables prefer the highest available patch level, but any patch level will do.
Different systems take slightly different approaches to finding the appropriate libraries at runtime. Sun systems have a fairly complex runtime loader that looks at all of the file names in the library directory and picks the best one. Linux systems use symbolic links to avoid the search process. If the latest version of the libc.so library is version 4.2.2, the library's name is libc_s.4.2.2, but the library is also linked to libc_s.4.2 so the loader need only open the shorter name and the correct version is selected.
Most systems permit shared libraries to reside in multiple directories. An environment variable such as LD_LIBRARY_PATH can override the path built into the executable, permitting developers to substitute library versions in their private directories for debugging or performance testing. (Programs that use the "set user ID" feature to run as other than the current user have to ignore LD_LIBRARY_PATH to prevent a malicious user from substituting a trojan horse library.)
Each format provides a trick to let the linker create a list of libraries that startup code can use to map in the libraries. COFF libraries use a brute force approach; ad hoc code in the linker creates a section in the COFF file with the names of the libraries. The Linux linker had a somewhat less brute force approach that created a special symbol type called a "set vector". Set vectors are treated like normal global symbols, except that if there are multiple definitions, the definitions are all put in an array named by the symbol. Each shared library stub defines a set vector symbol ___SHARED_LIBRARIES__ that is the address of a structure containing the name, version, and load address of the library. The linker creates an array of pointers to each of those structures and calls it ___SHARED_LIBRARIES__ so the runtime startup code can use it. The BSD/OS shared library scheme uses no linker tricks at all. Rather, the shell script wrapper used to create a shared executable runs down the list of libraries passed as arguments to the command or used implicitly (the C library), extracts the file names and load addresses for those libraries from a list in a system file, writes a little assembler source file containing an array of structures containing library names and load addresses, assembles that file, and includes the object file in the list of arguments to the linker.
In each case, the references from the program code to the library addresses are resolved automatically from the addresses in the stub library.
Linux added a single uselib() system call that took the file name and address of a library and mapped it into the program address space. The startup routine bound into the executable ran down the list of libraries, doing a uselib() on each.
The BSD/OS scheme uses the standard mmap() system call that maps pages of a file into the address space and a bootstrap routine that is linked into each shared library as the first thing in the library. The startup routine in the executable runs down the table of shared libraries, and for each one opens the file, maps the first page of the file to the load address, and then calls the bootstrap routine which is at a fixed location near the beginning of that page following the executable file header. The bootstrap routine then maps the rest of the text segment, the data segment, and maps fresh address space for the bss segment, then returns.
Once the segments are all mapped, there's often some library-specific initialization to do, for example, putting a pointer to the system environment strings in the global variable environ specified by standard C. The COFF implementation collects the initialization code from the .init segments in the program file, and runs it from the program startup code. Depending on the library it may or may not call routines in the shared library. The Linux implemention doesn't do any library initialization and documents the problem that variables defined in both the program and the library don't work very well.
In the BSD/OS implementation, the bootstrap routine for the C library receives a pointer to the table of shared libraries and maps in all of the other libraries, minimizing the amount of code that has to be linked into individual executables. Recent versions of BSD use ELF format executables. The ELF header has a interp section containing the name of an "interpreter" program to use when running the file. BSD uses the shared C library as the interpreter, which means that the kernel maps in the shared C library before the program starts, saving the overhead of some system calls. The library bootstrap routine does the same initializations, maps the rest of the libraries, and, via a pointer, calls the main routine in the program.
In a static library, all intra-library calls are permanently bound, and it's not possible to substitute a private version of a routine by redefining the routine in a program that uses the library. For the most part, that's not a problem since few programs redefine standard library routines like read() or strcmp(), or even if they do it's not a major problem if the program uses a private version of strcmp() while routines in the library call the standard version.
But a lot of programs define their own versions of malloc() and free(), the routines that allocate heap storage, and multiple versions of those routines in a program don't work. The standard strdup() routine, for example, returns a pointer to a string allocated by malloc, which the application can free when no longer needed. If the library allocated the string one version of malloc, but the application freed that string with a different version of free, chaos would ensue.
To permit applications to provide their own versions of malloc and free, the System V.3 shared C library uses an ugly hack, Figure 4. The system's maintainers redefined malloc and free as indirect calls through pointers bound into the data part of the shared library that we'll call malloc_ptr and free_ptr.
extern void *(*malloc_ptr)(size_t);
extern void (*free_ptr)(void
*);
#define malloc(s) (*malloc_ptr)(s)
#define free(s) (*free_ptr)(s)
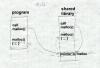 |
Figure 4: The malloc hack picture of program, shared C library. malloc pointer and init code indirect calls from library code |
Then they recompiled the entire C library, and added these lines (or the assembler equivalent) to the .init section of the stub library, so they are included in every program that uses the shared library.
#undef malloc
#undef free malloc_ptr = &malloc;
free_ptr
= &free;
Since the stub library is bound into the application, not the shared library, its references to malloc and free are resolved at the time each program is linked. If there's a private version of malloc and free, it puts pointers to them in the pointers, otherwise it will use the standard library version. Either way, the library and the application use the same version of malloc and free.
Although the implementation of this trick made maintenance of the library harder, and doesn't scale to more than a few hand-chosen names, the idea that intra-library calls can be made through pointers that are resolved at program runtime is a good one, so long as it's automated and doesn't require fragile manual source code tweaks. We'll find out how the automated version works in the next chapter.
Name conflicts in global data remain a problem with static shared libraries. Consider the small program in Figure 5. If you compile and link it with any of the shared libraries we described in this chapter, it will print a status code of zero rather than the correct error code. That's because
int errno;
defines a new instance of errno which isn't bound to the one in the shared library. If you uncomment the extern, the program works, because now it's an undefined global reference which the linker binds to the errno in the shared library. As we'll see, dynamic linking solves this problem as well, at some cost in performance.
| Figure 5: Address conflict example
|
Finally, even the jump table in Unix shared libraries has been known to cause compatibility problems. From the point of view of routines outside a shared library, the address of each exported routine in the library is the address of the jump table entry. But from the point of view of routines within the library, the address of that routine may be the jump table entry, or may be the real entry point to which the table entry jumps. There have been cases where a library routine compared an address passed as an argument to see if it were one of the other routines in the library, in order to do some special case processing.
An obvious but less than totally effective solution is to bind the address of the routine to the jump table entry while building the shared library, since that ensures that all symbolic references to routines within the library are resolved to the table entry. But if two routines are within the same object file, the reference in the object file is usually a relative reference to the routine's address in the text segment. (Since it's in the same object file, the routine's address is known and other than this peculiar case, there's no reason to make a symbolic reference back into the same object file.) Although it would be possible to scan relocatable text references for values that match exported symbol addresses, the most practical solution to this problem is ``don't do that'', don't write code that depends on recognizing the address of a library routine.
Windows DLLs have a similar problem, since within each EXE or DLL, the addresses of imported routines are considered to be the addresses of the stub routines that make indirect jumps to the real address of the routine. Again, the most practical solution to the problem is ``don't do that.''
If you look in a /shlib directory on a Unix system with shared libraries, you'll usually see three or four versions of each library with names like libc_s.2.0.1 and libc_s.3.0.0. Why not just have the most recent one?
In a stub library, why is it important to include all of the undefined globals for each routine, even if the undefined global refers to another routine in the shared library?
What difference would it make if a stub library were a single large executable with all of the library's symbols as in COFF or Linux, or an actual library with separate modules?
A shared library in our system is merely an object file which is linked at a given address. There can be no relocations and no unresolved symbol references, although references to other shared libraries are OK. Stub libraries are normal directory-format or file-format libraries, with each entry in the library containing the exported (absolute) and imported symbols for the corresponding library member but no text or data. Each stub library has to tell the linker the name of the corresponding shared library. If you use directory format stub libraries, a file called "LIBRARY NAME" contains lines of text. The first line is the name of the corresponding shared library, and the rest of the lines are the names of other shared libraries upon which this one depends. (The space prevents name collisions with symbols.) If you use file format libraries, the initial line of the library has extra fields:
LIBRARY nnnn pppppp fffff ggggg hhhhh ...
where fffff is the name of the shared library and the subsequent fields are the names of any other shared libraries on which it depends.
Project 9-1: Make the linker produce static shared libraries and stub libraries from regular directory or file format libraries. If you haven't already done so, you'll have to add a linker flag to set the base address at which the linker allocates the segments. The input is a regular library, and stub libraries for any other shared libraries on which this one depends. The output is an executable format shared library containing the segments of all of the members of the input library, and a stub library with a stub member corresponding to each member of the input library.
Project 9-2: Extend the linker to create executables using static shared libraries. Project 9-1 already has most of the work of searching stub libraries symbol resolution, since the way that an executable refers to symbols in a shared library is the same as the way that one shared library refers to another. The linker needs to put the names of the required libraries in the output file, so that the runtime loader knows what to load. Have the linker create a segment called .lib that contains the names of the shared libraries as strings with a null byte separating the strings and two null bytes at the end. Create a symbol _SHARED_LIBRARIES that refers to the beginning of the .lib section to which code in the startup routine can refer.