| Алгоритмы динамического управления памятью
| |
Герой имел привычку складывать окурки в
кожаный кисет и употреблять их для изготовления новых самокруток.
Таким образом, согласно велению неумолимого закона средних чисел,
какую-то часть этого табака он курил в течение многих лет.
Т. Пратчетт |
При динамическом выделении памяти запросы
на выделение памяти формируются во время исполнения задачи. Динамическое
выделение, таким образом, противопоставляется статическому,
когда запросы формируются на этапе компиляции программы. В конечном итоге,
и те, и другие запросы нередко обрабатываются одним и тем же алгоритмом
выделения памяти в ядре ОС. Но во многих случаях статическое выделение
можно реализовать намного более простыми способами, чем динамическое.
Главная сложность здесь в том, что при статическом выделении кажется неестественной
— и поэтому редко требуется — возможность отказаться от ранее выделенной
памяти. При динамическом же распределении часто требуется предоставить
возможность отказываться от запрошенных блоков так, чтобы освобожденная
память могла использоваться для удовлетворения последующих запросов. Таким
образом, динамический распределитель вместо простой границы между занятой
и свободной памятью (которой достаточно в простых случаях статического
распределения) вынужден хранить список возможно несвязных областей свободной
памяти, называемый пулом или кучей.
Многие последовательности запросов памяти и отказов от нее могут привести
к тому, что вся доступная память будет разбита на блоки маленького размера,
и попытка выделения большого блока завершится неудачей, даже если сумма
длин доступных маленьких блоков намного больше требуемой. Это явление
называется фрагментацией памяти (рис. 4.3).
Иногда используют более точный термин — внешняя фрагментация
(что такое внутренняя фрагментация будет рассказано далее). Кроме того,
большое количество блоков требует длительного поиска. Существует также
много мелких трудностей разного рода. К счастью, человечество занимается
проблемой распределения памяти уже давно и найдено много хороших или приемлемых
решений.
В зависимости от решаемой задачи используются различные стратегии поиска
свободных блоков памяти. Например, программа может выделять блоки одинакового
размера или нескольких фиксированных размеров. Это сильно облегчает решение
задач дефрагментации и поиска свободных участков ОЗУ.
Возможны ситуации, когда блоки освобождаются в порядке, обратном тому,
в котором они выделялись. Это позволяет свести выделение памяти к стеко-вой
структуре, т. е. фактически, вернуться к простому запоминанию границы
между занятой и свободной памятью.
Возможны также ситуации, когда некоторые из занятых блоков можно переместить
по памяти — тогда есть возможность проводить дефрагментацию
памяти, перемещение занятых блоков памяти с целью объединить свободные
участки. Например, функцию realloc() в ранних
реализациях системы UNIX можно было использовать именно для этой цели.

Рис. 4.3. Внешняя фрагментация
В стандартных библиотечных функциях языков высокого уровня, таких как
malloc/free/realloc в С, new/dispose
в Pascal и т. д., как правило, используются алгоритмы, рассчитанные на
наиболее общий случай: программа запрашивает блоки случайного размера
в случайном порядке и освобождает их также случайным образом.
Впрочем, случайные запросы — далеко не худший вариант. Даже не зная деталей
стратегии управления кучей, довольно легко построить программу, которая
"испортит жизнь" многим распространенным алгоритмам (пример
4.2).
Пример 4.2. Пример последовательности запросов
памяти
while(TRUE) {
void * bl = malloc(random (10)); /* Случайный размер от 0 до 10 байт */
void * Ь2 = malloc(random(lO)+10); Л ........ от 10 до 20 байт */
if(Ы == NULL && Ь2 == NULL) /* Если памяти нет */
break; /* выйти из цикла */
free(b1);
void * ЬЗ = malloc(150);
/* Скорее всего, память не будет выделена */
В результате исполнения такой программы вся доступная память будет "порезана
на лапшу": между любыми двумя свободными блоками будет размещен занятый
блок меньшего размера (рис. 4.4)

Рис. 4.4. Результат работы программы примера 4.2
К счастью, пример 4.2 имеет искусственный характер. В реальных программах
такая ситуация встречается редко, и часто оказывается проше исправить
программу, чем вносить изменения в универсальный алгоритм управления кучей.
Приведенный пример построен на том предположении, что система выделяет
нам блоки памяти, размер которых соответствует запрошенному с точностью
до байта. Если же минимальная единица выделения равна 32 байтам, никакой
внешней фрагментации наш пример не вызовет: на каждый запрос будет выделяться
один блок. Но при этом мы столкнемся с обратной проблемой, которая называется
внутренней фрагментацией: если система умеет рыделять только блоки, кратные
32 байтам, а нам реально нужно 15 или 47 байт, то 17 байт на блок окажутся
потеряны (рис. 4.5).
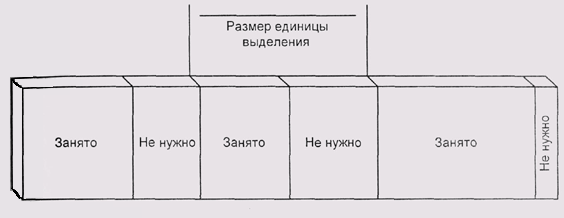
Рис. 4.5. Внутренняя фрагментация
Чем больше размер единицы выделения, тем меньше нам грозит фрагментация
внешняя, и тем большие потери обеспечивает фрагментация внутренняя. Величина
потерь зависит от среднего размера запрашиваемого блока. Грубая оценка
свидетельствует о том, что в каждом блоке в среднем теряется половина
единицы выделения, т. е. отношение занятой памяти к потерянной будет 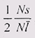 ,
где N— количество выделенных блоков, s— размер единицы выделения, а ,
где N— количество выделенных блоков, s— размер единицы выделения, а 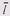 — средний размер блока. Упростив эту формулу, мы получим выражение для
величины потерь:
— средний размер блока. Упростив эту формулу, мы получим выражение для
величины потерь: 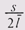 ,т. е. потери линейно растут с увеличением
размера единицы выделения. ,т. е. потери линейно растут с увеличением
размера единицы выделения.
Если средний размер блока сравним с единицей выделения, наша формула теряет
точность, но все равно дает хорошую оценку порядка величины потерь. Так,
если s = , наша формула дает 50% потерь, что вполне
согласуется Со здравым смыслом: если запрашиваемый блок чуть короче минимально
возможного, теряется только это "чуть"; зато если он чуть длиннее,
то для него отводится два минимальных блока, один из которых теряется
почти весь. Точная величина потерь определяется распределением запрашиваемых
блоков по длине, но мы предпочитаем оставить вывод точной формулы любопытному
читателю.
Варианты алгоритмов распределения памяти исследовались еше в 50-е году.
Итоги многолетнего изучения этой проблемы приведены в [Кнут 2000] и многих
других учебниках.
Обычно все свободные блоки памяти объединяются в двунаправленный связанный
список. Список должен быть двунаправленным для того, чтобы из него в любой
момент можно было извлечь любой блок. Впрочем, если все действия по извлечению
блока производятся после поиска, то можно слегка усложнить процедуру поиска
и всегда сохранять указатель на предыдущий блок. Это решает проблему извлечения
и можно ограничиться однонаправленным списком. Беда только в том, что
многие алгоритмы при объединении свободных блоков извлекают их из списка
в соответствии с адресом, поэтому для таких алгоритмов двунаправленный
список остро необходим.
Поиск в списке может вестись тремя способами: до нахождения первого
подходящего (first fit) блока, до блока, размер которого ближе
всего к заданному — наиболее подходящего (best fit),
и, наконец, до нахождения самого большого блока, наименее
подходящего (worst fit).
Использование стратегии worst fit имеет смысл разве что в сочетании с
сортировкой списка по убыванию размера. Это может ускорить выделение памяти
(всегда берется первый блок, а если он недостаточно велик, мы с чистой
совестью можем сообщить, что свободной памяти нет), но создает проблемы
при освобождении блоков: время вставки в отсортированный список пропорционально
О (n), где n —
размер списка.
Помещать блоки в отсортированный массив еще хуже — время вставки становится
О (n + log(n)) и появляется ограничение на
количество блоков. Использование хэш-таблиц или двоичных деревьев требует
накладных расходов и усложнений программы, которые себя в итоге не оправдывают.
На практике стратегия worst fit используется при размещении пространства
в файловых системах, например в HPFS, но ни одного примера ее использования
для распределения оперативной памяти автору неизвестно.
Чаще всего применяют несортированный список. Для нахождения наиболее подходящего
мы обязаны просматривать весь список, в то время как первый подходящий
может оказаться в любом месте, и среднее время поиска будет меньше. Насколько
меньше — зависит от отношения количества подходящих блоков к общему количеству.
(Читатели, знакомые с теорией вероятности, могут самостоятельно вычислить
эту зависимость.)
В общем случае best fit увеличивает фрагментацию
памяти. Действительно, если мы нашли блок с размером больше заданного,
мы должны отделить "хвост" и пометить его как новый свободный
блок. Понятно, что в случае best fit средний
размер этого "хвоста" будет маленьким, и мы в итоге получим
большое количество мелких блоков, которые невозможно объединить, так как
пространство между ними занято.
В тех ситуациях, когда мы размещаем блоки нескольких фиксированных размеров,
этот недостаток роли не играет и стратегия best fit может оказаться оправданной.
Однако библиотеки распределения памяти рассчитывают на обшпй случай, и
в них обычно используются алгоритмы first fit.
при использовании first fit с линейным двунаправленным списком возникает
специфическая проблема. Если каждый раз просматривать список с одного
и того же места, то большие блоки, расположенные ближе к началу, будут
чаще удаляться. Соответственно, мелкие блоки будут скапливаться в начале
списка, что увеличит среднее время поиска (рис. 4.6). Простой способ борьбы
с этим явлением состоит в том, чтобы просматривать список то в одном направлении,
то в другом. Более радикальный и еще более простой метод заключается в
следующем: список делается кольцевым, и каждый поиск начинается с того
места, где мы остановились в прошлый раз. В это же место добавляются освободившиеся
блоки. В результате список очень эффективно перемешивается и никакой "антисортировки"
не возникает.
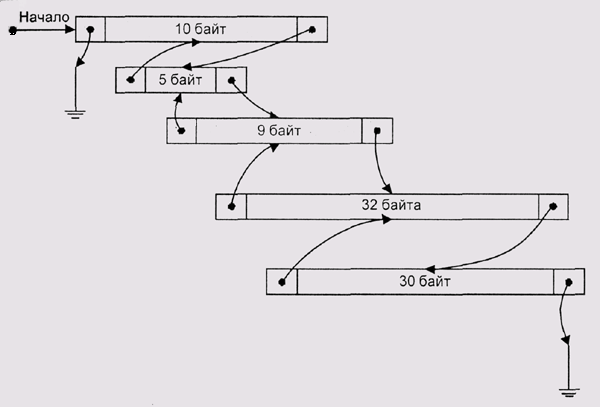
Рис. 4.6. Антисортировка
Разработчик программы динамического распределения памяти обязан решить
еще одну важную проблему, а именно — объединение свободных блоков. Действительно,
обидно, если мы имеем сто свободных блоков по одному килобайту и не можем
сделать из них один блок в 100 килобайт. Но если все эти блоки расположены
в памяти один за другим, а мы не можем их при этом объединить — это просто
унизительно.
Кроме того, если мы умеем объединять блоки и видим, что объединенный блок
ограничен сверху значением brkievel, то мы можем,
вместо помещения этого блока в список, просто уменьшить значение brkievel
и, таким образом, вернуть ненужную память системе.
Представим себе для начала, что все, что мы знаем о блоке, — это его начальный
адрес и размер. Легко понять, что это очень плохая ситуация. Действительно,
для объединения блока с соседями мы должны найти их в списке свободных,
или же убедиться, что там их нет. Для этого мы должны просмотреть весь
список. Как одну из идей мозгового штурма можно выдвинуть предложение
сортировать список свободных блоков по адресу.
Гораздо проще запоминать в дескрипторе блока указатели на дескрипторы
соседних блоков. Немного развив эту идею, мы приходим к методу, который
называется алгоритмом парных меток и состоит
в том, что мы добавляем к каждому блоку по два слова памяти. Именно слова,
а не байта. Дело в том, что требуется добавить достаточно места, чтобы
хранить в нем размер блока в байтах или словах. Обычно такое число занимает
столько же места, сколько и адрес, а размер слова обычно равен размеру
адреса. На х86 в реальном режиме это не так, но это вообще довольно странный
процессор.
Итак, мы добавляем к блоку два слова — одно перед ним, другое после него.
В оба слова мы записываем размер блока. Получается своеобразный дескриптор,
который окружает блок. При этом мы устанавливаем, что значения длин будут
положительными, если блок свободен, и отрицательными, если блок занят.
Можно сказать и наоборот, важно только потом соблюдать это соглашение
(рис. 4.7).
Представим, что мы освобождаем блок с адресом addr.
Считаем, что addr имеет
тип word *, и при добавлении к нему целых чисел
результирующий адрес будет отсчитываться в словах, как в языке С. Для
того чтобы проверить, свободен ли сосед перед ним, мы должны посмотреть
слово с адресом addr 2. Если оно отрицательно,
то сосед занят, и мы должны оставить его в покое (рис. 4.8). Если же оно
положительно, то мы можем легко определить адрес начала этого блока как
addr - addr[-2].
Определив адрес начала блока, мы можем легко объединить этот блок с блоком
addr, нам нужно только сложить значения меток-дескрипторов
и записать их в дескрипторы нового большого блока. Нам даже не нужно будет
добавлять освобождаемый блок в список и извлекать оттуда его соседа!
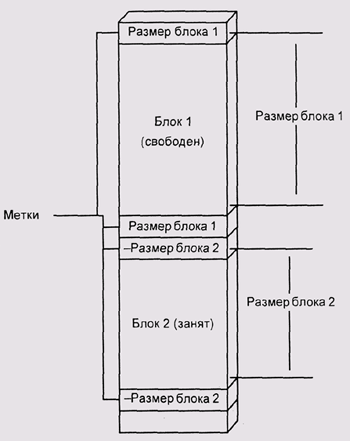
Рис. 4.7. Парные метки
Похожим образом присоединяется и сосед, стоящий после него. Единственное
отличие состоит в том, что этого соседа все-таки нужно извлекать из списка
свободных блоков.
Фактически, парные метки можно рассматривать как способ реализации решения,
предложенного нами как одна из идей мозгового штурма: двунаправленного
списка, включающего в себя как занятые, так и свободные блоки, и отсортированного
по адресу. Дополнительное преимущество приведенного алгоритма состоит
в том, что мы можем отслеживать такие ошибки, как многократное освобождение
одного блока, запись в память за границей блока и иногда даже обращение
к уже освобожденному блоку. Действительно, мы в любой момент можем проверить
всю цепочку блоков памяти и убедиться в том, что все свободные блоки стоят
в списке, что в нем стоят только свободные блоки, что сами цепочка и список
не испорчены и т. д.
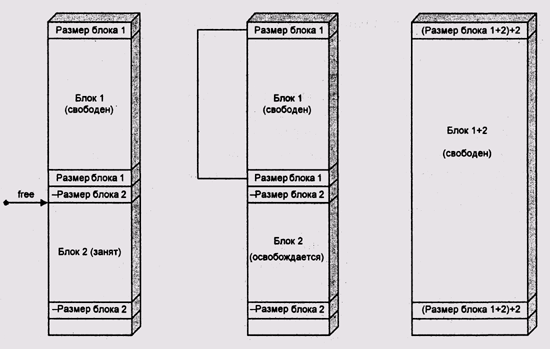
Рис. 4.8. Объединение с использованием парных меток
Примечание
Это действительно большое преимущество, так как оно значительно облегчает
выявление ошибок работы с указателями, о которых в руководстве по Zortech
C/C++ сказано, что "опытные программисты, услышав это слово [ ошибка
работы с указателями — прим. авт.], бледнеют и прячутся под стол"
([Zortech v3.xj).
Итак, наилучшим из известных универсальных алгоритмов динамического
распределения памяти является алгоритм парных меток
с объединением свободных блоков в двунаправленный кольцевой список
и поиском по принципу first fit. Этот алгоритм обеспечивает приемлемую
производительность почти для всех стратегий распределения памяти, используемых
в прикладных программах.
Алгоритм парных меток был предложен Дональдом Кнутом в начале 60-х. В
третьем издании классической книги [Кнут, 2000], этот алгоритм приводится
под названием "освобождения с дескрипторами границ". В современных
системах используются и более сложные структуры дескрипторов, но всегда
ставится задача обеспечить поиск соседей блока по адресному про' странству
за фиксированное время. В этом смысле, практически все современные подпрограммы
динамического выделения памяти (в частности, реализации стандартной библиотеки
языка С) используют аналоги алгоритма парных меток. Другие известные подходы
либо просто хуже, чем этот, либо проявляют свои преимущества только в
специальных случаях.
Реализация maiioc в библиотеке GNU LibC (реализация
стандартной биб-иотеки языка С в рамках freeware проекта GNU Not Unix)
(пример 4.3) использует смешанную стратегию: блоки размером более 4096
байт выделяются стратегией first fit из двусвязного кольцевого списка
с использованием щклического просмотра, а освобождаются при помощи метода,
который в мазанном ранее смысле похож на алгоритм парных меток. Все выделяемые
образом блоки будут иметь размер, кратный 4096 байтам.
Блоки меньшего размера объединяются в очереди с размерами, пропорциональными
степеням двойки, как в описанном далее алгоритме близнецов. Элементы этих
очередей называются фрагментами (рис. 4.9). В отличие от алгоритма близнецов,
мы не объединяем при освобождении парные фрагменты. Вместо этого, мы разбиваем
4-килобайтовый блок на фрагменты одинакового размера. Если, например,
наша программа сделает запросы на 514 и 296 байт памяти, ей будут переданы
фрагменты в 1024 и 512 байт соответственно. Под эти фрагменты будут выделены
полные блоки в 4 килобайта, и внутри них будет выделено по одному фрагменту.
При последующих запросах на фрагменты такого же размера будут использоваться
свободные фрагменты этих блоков. Пока хотя бы один фрагмент блока занят,
весь блок считается занятым. Когда же освобождается последний фрагмент,
блок возвращается в пул.
Описатели блоков хранятся не вместе с самими блоками, а в отдельном динамическом
массиве _heapihfo. Описатель заводится не на
непрерывную последовательность свободных байтов, а на каждые 4096 байт
памяти (в примере 4.3 именно это значение принимает константа
BLOCKSIZE). Благодаря этому мы можем вычислить индекс описателя
в _heapinfo, просто разделив на 4096 смещение
освобождаемого блока от начала пула.
Для нефрагментированных блоков описатель хранит состояние (занят-свободен)
и размер непрерывного участка, к которому принадлежит блок. Благодаря
этому, как и в алгоритме парных меток, мы легко можем найти соседей освобождаемого
участка памяти и объединить их в большой непрерывный участок.
Для фрагментированных блоков описатель хранит размер фрагмента, счетчик
занятых фрагментов и список свободных. Кроме того, все свободные Фрагменты
одного размера объединены в общий список — заголовки этих
списков собраны в массив _f raghead.
Используемая структура данных занимает больше места, чем применяемая в
Классическом алгоритме парных меток, но сокращает объем списка свободных
блоков и поэтому имеет более высокую производительность. Средний oбъем
блока, выделяемого современными программами для ОС общего назначения,
измеряется многими килобайтами, поэтому в большинстве случа-ев повышение
накладных расходов памяти оказывается терпимо.
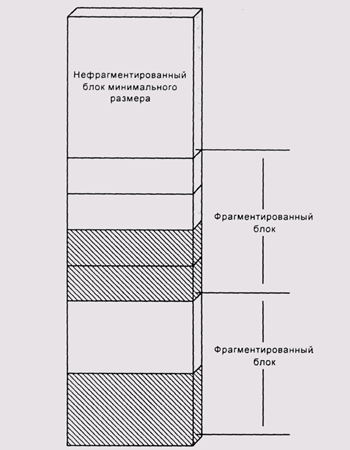
Рис. 4.9. Фрагменты в реализации malloc из GNU LibC
Пример 4.3. Реализация malloc/fгее
в GNU LibC. Функция__default_morecore
приведена в примере 4.1.
malloc.с
/* Распределитель памяти 'malloc'.
Copyright 1990, 1991, 1992 Free Software Foundation Написана в мае 1989
Mike Haertel.
GNU С Library является свободным программным обеспечением;
вы можете передавать другим лицам и/или модифицировать ее в соответствии
с положениями GNU General Public License версии 2 или (по вашему выбору)
любой более поздней версии.
библиотека GNU С распространяется в надежде, что она будет полезна, но
БЕЗ КАКИХ-ЛИБО ГАРАНТИЙ; даже без неявно предполагаемых гарантий
КОММЕРЧЕСКОЙ ЦЕННОСТИ или ПРИГОДНОСТИ ДЛЯ КОНКРЕТНОЙ ЦЕЛИ.
Подробнее см. GNU General Public License.
ВЫ должны были получить копию GNU General Public License вместе с
GNU С Library; см. файл COPYING. Если вы ее не получили, напишите по адресу:
Free Software Foundation, 675 Mass Ave, Cambridge, MA 02139, USA.
С автором можно связаться по электронной почте по адресу mike@ai.rait.edu,
или Mike Haertel с/о Free Software Foundation. */
# ifndef _MALLOC_INTERNAL
#define _MALLOC_INTERNAL tinclude <malloc.h>
#endif
#ifdef __ELF_
ipragma weak malloc = __libc_malloc
#endif
/* Как действительно получить дополнительную память. */
__ptr_t (*__morecore) __Р ((ptrdiff_t __size))
= __default_morecore_init;
/* Предоставляемая пользователем отладочная функция (hook) для xmalloc'
*/
void (*__malloc_initialize_hook) __P ((void));
__ptr_t (*_malloc_hook) __P ((size_t __size)) ;
/* Указатель на основание первого блока. */ char *_heapbase;
* Таблица информационных записей о блоках. Размещается
через align/__free (не malloc/free). */
malloc_info *_heapinfo;
/* Количество информационных записей. */ static size_t heapsize;
/* Индекс поиска в информационной таблице. */ size_t _heapindex;
/* Ограничитель допустимых индексов в информационной таблице */ size_t
_heaplimit;
#if 1 /* Adapted from Mike */
/* Счетчик больших блоков, размещенных для каждого из размеров
фрагментов. */
int _fragblocks[BLOCKLOG];
#endif
/* Списки свободных фрагментов по размерам.
*/ struct list _fraghead[BLOCKLOG];
/* Инструментальные переменные.
*/ size_t __chunks_used; size_t _bytes_used; size_t _chunks_free; size_t
_bytes_free;
/* Имеем ли мы опыт? */
/* Are you experienced? */
int malloc initialized;
/* Выровненное размещение. */
static __ptr_t align __P ((size_t));
static __ptr_t
align (size)
size_t size; {
__ptr_t result;
unsigned long int adj;
[result = (*__morecore) (size);
adj = (unsigned long int) ((unsigned long int) ((char *) result -
(char *) NULL)) % BLOCKSIZE; lit (adj != 0)
{
adj = BLOCKSIZE - adj; (void) (*_morecore) (adj); result = (char *) result
+ adj;
}
return result;
/* Настроить все и запомнить, что у нас есть. */
/* Set everything up and remember that we have.
*/ static int initialize _ P ( (void) ) ; static int initialize ()
{ if ( malloc initialize hook)
(*__malloc_initialize_hook) ();
heaps ize = HEAP / BLOCKSIZE;
_heapinfo = (malloc_info *) align (heapsize * sizeof (malloc_info) ) ;
if (_heapinfo == NULL)
return 0;
memset (_heapinfo, 0, heapsize * sizeof (malloc_info) ) ; _heapinfo [0]
. f ree. size = 0;
_heapinfo[0] .free. next = _heapinfo[0] . free.prev = 0; _heapindex =
0;
_heapbase = (char *) _heapinfo; __malloc_initialized = 1; return 1;
/* Получить выровненную память, инициализируя
или наращивая таблицу описателей кучи по мере необходимости. static _
ptr_t morecore _ P ( (size_t) ) ; static _ ptr_t ,Шогесоге (size)
size_t size;
_ ptr_t result;
malloc_info *newinfo, *oldinfo;
size_t newsize;
result = align (size) ; if (result == NULL) return NULL;
/* Проверить, нужно ли нам увеличить таблицу описателей. */ if ((size_t)
BLOCK ((char *) result + size) > heapsize) I
newsize = heapsize;
while ( (size_t) BLOCK ((char *) result + size) > newsize)
newsize *= 2;
newinfo = (malloc_info *) align (newsize * sizeof (malloc_info) ) if (newinfo
== NULL) {
(* _ morecore) (-size); return NULL; }
memset (newinfo, 0, newsize * sizeof (malloc_info) ) ; memcpy (newinfo,
_heapinfo, heapsize * sizeof (malloc_info) ) ; oldinfo = _heapinfo;
newinfo[BLOCK (oldinfo) ] .busy. type = 0; newinfo [BLOCK (oldinfo) ]
.busy. info. size
= BLOCKIFY (heapsize * sizeof (malloc_info) ) ; _heapinfo = newinfo; _free_internal
(oldinfo) ; heapsize = newsize;
_heaplimit = BLOCK ((char *) result + size) ; return result; I
/* Выделить память из кучи. */ ptr t
Глава 4. Управление оперативнои
libcjnalloc (size) size_t size;
I
ptr_t result;
size t block, blocks, lastblocks, start; register size_t i; struct list
*next;
/* Некоторые программы вызывают malloc (0) . Мы это допускаем. */
lif °
if (size == 0)
return NULL; #endif
if (! malloc initialized) if ( '.initialize () ) return NULL;
if ( _ malloc_hook != NULL)
return (*__malloc_hook) (size) ;
if (size < sizeof (struct list) ) size = sizeof (struct list) ;
/* Определить политику размещения на основании размера запроса. */ if
(size <= BLOCKSIZE / 2) {
/* Маленькие запросы получают фрагмент блока.
Определяем двоичный логарифм размера фрагмента.
*/ register size_t log = 1; — size; while ( (size /= 2) != 0)
/* Просмотреть списки фрагментов на предмет свободного
фрагмента желаемого размера. */ next = _f raghead[ log] .next; if (next
!= NULL)
I
введение в операционные системы
/* Найдены свободные фрагменты этого размера.
Вытолкнуть фрагмент из списка фрагментов и вернуть его. Обновить счетчики
блока nfree и first.
*/ result = ( _ ptr_t) next; next->prev->next = next->next; if
(next->next != NULL)
next->next->prev = next->prev; block = BLOCK (result); if
( — _heapinf о [block] .busy. info. frag. nfree != 0)
_heapinfo [block] .busy. info. frag. first = (unsigned long int)
((unsigned long int) ((char *) next->next — (char *) NULL) % BLOCKSIZE)
» log;
/* Обновить статистику. */
++_chunks_used;
_bytes_used += 1 « log;
--_chunks_f ree ;
_bytes_free -= 1 « log; t
else
/* Нет свободных фрагментов желаемого размера. Следует взять новый блок;
поделить его на фрагменты и вернуть первый. */ result = _ libc_malloc
(BLOCKSIZE) ; if (result == NULL)
return NULL; #if 1 /* Adapted from Mike */
++_fragblocks [log] ; #endif
/* Связать все фрагменты, кроме первого, в список свободных. */ for (i
= 1; i < (size_t) (BLOCKSIZE » log); ++i) I
next = (struct list *) ((char *) result + (i « log)); next->next =
_fraghead[log] .next; next->prev = &_fraghead[log] ; next->prev->next
= next; if (next->next != NULL) next->next->prev = next;
}
/* Инициализировать счетчики nfree и first для этого блока. */ block =
BLOCK (result); _heapinfо[block].busy.type = log;
_heapinfо[block].busy.info.frag.nfree = i — I; heapinfo[block].busy.info.frag.first
= i — 1;
_chunks_free += (BLOCKSIZE » log) - 1;
_bytes_free += BLOCKSIZE - (1 « log); _bytes_used -= BLOCKSIZE - (1 «
log);
} else
{
/* Большие запросы получают один или больше блоков.
Просмотреть список свободных циклически, начиная с точки, где мы были
в последний раз. Если мы пройдем полный круг, не обнаружив достаточно
большого блока, мы должны будем запросить еще память у системы. */
blocks = BLOCKIFY (size);
start = block = _heapindex;
while (_heapinfо[block].free.size < blocks)
block = _heapinfо[block].free.next; if (block == start)
/* Необходимо взять больше [памяти] у системы.
Проверить, не будет ли новая память продолжением последнего свободного
блока; если это так, нам не надо будет запрашивать так много.
*/ block = _heapinfo[0].free.prev; lastblocks = _heapinfо[block].free.size;
if (_heaplimit != 0 && block + lastblocks == _heaplimit &&
(*__morecore) (0) == ADDRESS (block + lastblocks) &&
(morecore ((blocks - lastblocks) * BLOCKSIZE)) != NULL)
tif 1
/* Adapted from Mike */ Л
Обратите внимание, что morecore() может изменить
и дудение в операционные системы
положение последнего блока, если она перемещает таблицу дескрипторов и
старая копия таблицы сливается с последним блоком. */ block = _heapinfo[0].free.prev;
_heapinfо[block].free.size += blocks — lastblocks; #else
_heapinfо[block].free.size = blocks; tendif
_bytes_free += (blocks - lastblocks) * BLOCKSIZE; continue; }
result = raorecore (blocks * BLOCKSIZE); if (result == NULL)
return NULL; block = BLOCK (result);
_heapinfо[block].busy.type = 0; _heapinfo[block].busy.info.size = blocks;
++ chunks used;
_bytes_used += blocks * BLOCKSIZE; return result;
/* В этой точке мы [так или иначе] нашли подходящую запись в списке свободных.
Понять, как удалить то, что нам нужно, из списка. */ result = ADDRESS
(block); if (_heapinfо[block].free.size > blocks) {
/* Блок, который мы нашли, имеет небольшой остаток,
так что присоединить его задний конец к списку свободных. */ _heapinfо[block
+ blocks].free.size
= _heapinfo[block].free.size - blocks; _heapinfo[block + blocks].free.next
= _heapinfо[block].free.next; _heapinfo[block + blocks].free.prev
= _heapinfо[block].free.prev;
_heapinfo[_heapinfo[block].free.prev].free.next = _heapinfo[_heapinfo[block].free.next].free.prev
= _heapindex = block + blocks
else
I^H
/* Блок точно соответствует нашему запросу, поэтому
просто удалить его из списка. */ _heapinfo[_heapinfo[block] .free. next]
.free.prev
= _heapinf о [block] . free.prev; _heapinfo[_heapinfo[block] .free.prev]
.free. next
= _heapindex = _heapinf о [block] . free. next; — chunksf ree ;
_heapinf о [block] .busy. type = 0;
_heapinf о [block] .busy . info. size = blocks;
++_chunks_used;
_bytes_used += blocks * BLOCKSIZE;
_bytes_free -= blocks * BLOCKSIZE;
return result;
free. c:
/* Освободить блок памяти, выделенный "malloc1.
Copyright 1990, 1991, 1992 Free Software Foundation Написано в мае 1989
Mike Haertel.
GNU С Library является свободным программным обеспечением; вы можете перераспространять
ее и/или модифицировать ее в соответствии с положениями GNU General Public
License версии 2 или (по вашему выбору) любой более поздней версии.
Библиотека GNU С распространяется в надежде, что она будет полезна, но
БЕЗ КАКИХ-ЛИБО ГАРАНТИЙ; даже без неявно предполагаемых гарантий
КОММЕРЧЕСКОЙ ЦЕННОСТИ или ПРИГОДНОСТИ для КОНКРЕТНОЙ ЦЕЛИ.
Подробнее см. GNU General Public License.
С автором можно связаться по электронной почте по адресу mike@ai.mit.edu,
или Mike Haertel с/о Free Software Foundation. */
#ifndef _MALLOC_INTERNAL #define _MALLOC_INTERNAL tinclude <malloc.h>
tendif
#ifdef __ELF_
tpragma weak free = __libc_free
#endif
/^Предоставляемая пользователем отладочная функция (hook) для 4free'.
*/ void (*__free_hook) __P ((__ptr_t __ptr));
/* Список блоков, вьщеленных memalign. */ struct alignlist *_aligned_blocks
= NULL;
/* Вернуть память в кучу. Аналогична 'free' но не вызывает
__free_hook даже если он определен. */
void _free_internal (ptr)
__ptr_t ptr;
{
int type;
size_t block, blocks;
register size_t i;
struct list *prev, *next;
block = BLOCK (ptr);
type = _heapinfо[block].busy.type; switch (type) { case 0:
/* Собрать как можно больше статистики как можно раньше. */ — chunks used;
-I—----
_bytes_used -= heapinfo [block] .busy. info. size * BLOCKSIZE; bytes_free
+= heapinfo [block] .busy. info. size * BLOCKSIZE;
/* Найти свободный кластер, предшествующий этому в списке свободных .
Начать поиск с последнего блока, к которому было обращение. Это может
быть преимуществом для программ, в которых выделение локальное. */ i =
_heapindex; if (i > block)
while (i > block)
i = _heapinfo[i) . free.prev; else { do
i = __heapinfo[i] . free. next; while (i > 0 && i < block)
; i = _heapinfo [i] . free.prev; 1
/* Определить, как включить этот блок в список свободных. */
if (block == i + _heapinfo[i] . free. size) {
/* Слить этот блок с его предшественником. */ _heapinfo[i] .free. size
+= _heapinfo [block] .busy. info. size/block = i;
else
/* Действительно включить этот блок в список свободных. */
_heapinf о [block] . free. size = _heapinfo [block] .busy. info. size;
_heapinf о [block] .free. next = _heapinfo[i] . free. next;
_heapinf о [block] . free.prev = i;
_heapinfo[i] .free. next = block;
_heapinf о [_heapinfo [block] .free. next] .free.prev = block;
++chunksfree;
/* Теперь, поскольку блок включен, проверить, не можем ли мы
слить его с его последователем (исключая его последователя из списка и
складывая размеры) . */
if (block + _heapinf о [block] . free. size == heapinfo [block] .free.
next)
{ _heapinfo [block] .free. size
+= _heapinfo [_heapinfo [block] .free. next] . free. size; _heapinfo [block]
.free. next
= _heapinfo[_heapinfo[block] .free. next] . free. next ; _heapinf о [_heapinfo[block]
.free. next] .free. prev = block; — chunksf ree ;
/* Проверить, не можем ли мы вернуть память системе. */
blocks = _heapinf о [block] .free. size;
if (blocks >= FINAL_FREE_BLOCKS && block + blocks == _heaplimit
&& (*_morecore) (0) == ADDRESS (block + .blocks)) {
register size_t bytes = blocks * BLOCKSIZE; _heaplimit -= blocks;
(*__morecore) (-bytes); _heapinf о [_heapinf о [block] .free. prev] .free.
next
= _heapinf о [block] . free. next; _heapinfo[_heapinfo[block] .free. next]
.free. prev
= _heapinf о [block] . free. prev; block = _heapinf о [block] . free.
prev; — _chunks_f ree ; _bytes_free -= bytes;
/* Установить следующий поиск, стартовать с этого блока. */
_heapindex = block; break;
default:
/* Собрать некоторую статистику. */
—_chunks_used; _bytes_used -= 1 « type; ++_chunks_free; bytes_free +=
1 « type;
/* Получить адрес первого свободного фрагмента в этом блоке.
*/ prev = (struct list *) ((char *) ADDRESS (block) +
(_heapinfo[block].busy.info.frag.first « type));
#if 1 /* Adapted from Mike */
if (_heapinfо[block].busy.info.frag.nfree == (BLOCKSIZE » type) - 1
&& _fragblocks[type] > 1) #else
if (_heapinfо[block].busy.info.frag.nfree == (BLOCKSIZE » type) - 1)
#endif
lif 1 #endii
/* Если все фрагменты этого блока свободны, удалить их из списка фрагментов
и освободить полный блок. */ /* Adapted from Mike */
— _f ragblocks [type] ;
next = prev;
for (i = 1; i < (size_t) (BLOCKSIZE » type)
next = next->next; prev->prev->next = next; if (next != NULL)
next->prev = prev->prev; _heapinf о [block] .busy. type = 0; _heapinf
о [block] .busy . info. size = 1;
/* Следим за точностью статистики.
*/ ++_chunks_used; _bytes_used += BLOCKSIZE; _chunks_free -= BLOCKSIZE
» type; _bytes_free -= BLOCKSIZE;
libc free (ADDRESS (block));
I
else if ( heapinfо[block].busy.info.frag.nfree != 0)
/* Если некоторые фрагменты этого блока свободны, включить
этот фрагмент в список фрагментов после первого свободного фрагмента этого
блока. */
next = (struct list *) ptr;
next->next = prev->next;
next->prev = prev;
prev->next = next;
if (next->next != NULL) next->next->prev = next;
++_heapinfо[block].busy.info.frag.nfree;
else
/* В этом блоке нет свободных фрагментов, поэтому включить этот фрагмент
в список фрагментов и анонсировать, что это первый свободный фрагмент
в этом блоке. */
prev = (struct list *) ptr;
_heapinfo [block] .busy. info. frag. nfree = 1;
_heapinfo [block] .busy. info. frag. first = (unsigned long int)
((unsigned long int) ((char *) ptr - (char *) NULL) % BLOCKSIZE » type)
; prev->next = _fraghead[type] .next; prev->prev = &_fraghead[type]
; prev->prev->next = prev; if (prev->next != NULL)
prev->next->prev = prev;
break;
/* Вернуть память в кучу. */ void
_ libc_free (ptr) _ ptr_t ptr; {
register struct alignlist *1;
if (ptr == NULL) return;
for (1 = _aligned_blocks; 1 != NULL; 1 = l->next) if (l->aligned
== ptr)
{
l->aligned = NULL;
/* Пометить элемент списка как свободный. */
ptr = l->exact;
break;
if ( _ free_hook != NULL) (* _ free_hook) (ptr) ;
else
_free_internal (ptr) ;
#include <gnu-stabs . h>
#ifdef elf_alias
elf_alias (free, cfree) ;
#endif
К основным недостаткам этого алгоритма относится невозможность оценки
времени поиска подходящего блока, что делает его неприемлемым для задач
реального времени. Для этих задач требуется алгоритм, который способен
за фиксированное (желательно, небольшое) время либо найти подходящий блок
памяти, либо дать обоснованный ответ о том, что подходящего блока не существует.
Проще всего решить эту задачу, если нам требуются блоки нескольких фиксированных
размеров (рис. 4.10). Мы объединяем блоки каждого размера в свой список.
Если в списке блоков требуемого размера ничего нет, мы смотрим в список
блоков большего размера. Если там что-то есть, мы разрезаем этот блок
на части, одну отдаем запрашивающей программе, а вторую... Правда, если
размеры требуемых блоков не кратны друг другу, что мы будем делать с остатком?
Для решения этой проблемы нам необходимо ввести какое-либо ограничение
на размеры выделяемых блоков. Например, можно потребовать, чтобы эти размеры
равнялись числам Фибоначчи (последовательность целых чисел, в которой
Fi+1 = Fi + Fi-1. В этом случае, если
нам нужно Fi байт, а в наличии есть только блок размера Fi+1,
мы легко можем получить два блока — один требуемого размера, а другой
— Fi-1, который тоже не пропадет. Да, любое ограничение на
размер приведет к внутренней фрагментации, но так ли велика эта плата
за гарантированное время поиска блока?

Рис. 4.10. Выделение блоков фиксированных размеров
На практике, числа Фибоначчи не используются. Одной из причин, по-видимому,
является относительная сложность вычисления такого Fi, которое
не меньше требуемого размера блока. Другая причина — сложность объединения
свободных блоков со смежными адресами в блок большего размера. Зато широкое
применение нашел алгоритм, который ограничивает последовательные размеры
блоков более простой зависимостью — степенями числа 2: 512 байт, 1 Кбайт,
2 Кбайт и т. д. Такая стратегия называется алгоритмом
близнецов (рис. 4.11).
Одно из преимуществ этого метода состоит в простоте объединения блоков
при их освобождении. Адрес блока-близнеца получается простым инвертированием
соответствующего бита в адресе нашего блока. Нужно только проверить, свободен
ли этот близнец. Если он свободен, то мы объединяем братьев в блок вдвое
большего размера, и т. д. Даже в наихудшем случае время поиска не превышает
О (log(Smax)-log(Smin)), где Smax и Smin
обозначают, соответственно, максимальный и минимальный размеры используемых
блоков. Это делает алгоритм близнецов трудно заменимым для ситуаций, в
которых необходимо гарантированное время реакции — например, для
задач реального времени. Часто этот алгоритм или его варианты используются
для выделения памяти внутри ядра ОС.
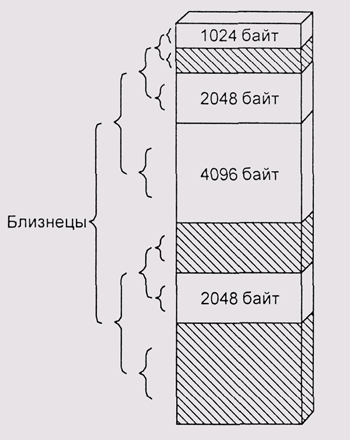
Рис. 4.11. Алгоритм близнецов
Существуют и более сложные варианты применения описанного выше подхода.
Например, пул свободной памяти Novell Netware состоит из 4 очередей с
шагом 16 байт (для блоков размерами 16, 32, 48, 64 байта), 3 очередей
с шагом 64 байта (для блоков размерами 128, 192, 256 байт) и пятнадцати
очередей с шагом 256 байт (от 512 байт до 4 Кбайт). При запросах большего
размера выделяется целиком страница. Любопытно, что возможности работы
в режиме реального времени, присущие этой изощренной стратегии, в Netware
практически не используются.
Например, если драйвер сетевого интерфейса при получении очередного пакета
данных обнаруживает, что у него нет свободных буферов для его приема,
он не пытается выделить новый буфер стандартным алгоритмом. Вместо этого,
драйвер просто игнорирует пришедшие данные, лишь увеличивая счетчик потерянных
пакетов. Отдельный системный процесс следит за состоянием этого счетчика
и только при превышении им некоторого порога за некоторый интервал времени
выделяет драйверу новый буфер.
Подобный подход к пользовательским данным может показаться циничным, Но
надо вспомнить, что при передаче данных по сети возможны и другие Причины
потери пакетов, например порча данных из-за электромагнитных Помех. Поэтому
все сетевые протоколы высокого уровня предусматривают средства пересылки
пакетов в случае их потери, какими бы причинами эта потеря ни была вызвана.
С другой стороны, в системах реального времени игнорирование данных, которые
мы все равно не в состоянии принять и обработать, — довольно часто используемая,
хотя и не всегда приемлемая стратегия.
|


