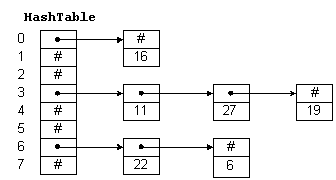
При добавлении элементов в хеш-таблицу выделяются куски динамической памяти, которые организуются в виде связанных списков, каждый из которых соответствует входу хеш-таблицы. Этот метод называется связыванием. Другой метод, в котором все элементы располагаются в самой хеш-таблице, известен как прямая или открытая адресация; его описание вы найдете в цитируемой литературе.
Если хеш-функция распределяет совокупность возможных ключей равномерно по множеству индексов, то хеширование эффективно разбивает множество ключей. Наихудший случай - когда все ключи хешируются в один индекс. При этом мы работаем с одним линейным списком, который и вынуждены последовательно сканировать каждый раз, когда что-нибудь делаем. Отсюда видно, как важна хорошая хеш-функция. Здесь мы рассмотрим лишь несколько из возможных подходов. При иллюстрации методов предполагается, что unsigned char располагается в 8 битах, unsigned short int - в 16, unsigned long int - в 32.
typedef int HashIndexType;
HashIndexType Hash(int Key) {
return Key % HashTableSize;
}
Для успеха этого метода очень важен выбор подходящего значения hashTableSize.
Если, например, hashTableSize равняется двум, то для четных ключей
хеш-значения будут четными, для нечетных - нечетными. Ясно, что это нежелательно
- ведь если все ключи окажутся четными, они попадут в один элемент таблицы.
Аналогично, если все ключи окажутся четными, то hashTableSize, равное
степени двух, попросту возьмет часть битов Key в качестве индекса.
Чтобы получить более случайное распределение ключей, в качестве hashTableSize
нужно брать простое число, не слишком близкое к степени двух.
Пусть, например, размер таблицы hashTableSize равен 1024 (210). Тогда нам достаточен 16-битный индекс и S будет присвоено значение 16 - 10 = 6. В итоге получаем:/* 8-bit index */ typedef unsigned char HashIndexType; static const HashIndexType K = 158; /* 16-bit index */ typedef unsigned short int HashIndexType; static const HashIndexType K = 40503; /* 32-bit index */ typedef unsigned long int HashIndexType; static const HashIndexType K = 2654435769; /* w=bitwidth(HashIndexType), size of table=2**m */ static const int S = w - m; HashIndexType HashValue = (HashIndexType)(K * Key) >> S;
typedef unsigned short int HashIndexType;
HashIndexType Hash(int Key) {
static const HashIndexType K = 40503;
static const int S = 6;
return (HashIndexType)(K * Key) >> S;
}
typedef unsigned char HashIndexType;
HashIndexType Hash(char *str) {
HashIndexType h = 0;
while (*str) h += *str++;
return h;
}
typedef unsigned char HashIndexType;
unsigned char Rand8[256];
HashIndexType Hash(char *str) {
unsigned char h = 0;
while (*str) h = Rand8[h ^ *str++];
return h;
}
Здесь Rand8 - таблица из 256 восьмибитовых случайных чисел. Их точный
порядок не критичен. Корни этого метода лежат в криптографии; он оказался
вполне эффективным (Pearson
[1990]).
typedef unsigned short int HashIndexType;
unsigned char Rand8[256];
HashIndexType Hash(char *str) {
HashIndexType h;
unsigned char h1, h2;
if (*str == 0) return 0;
h1 = *str; h2 = *str + 1;
str++;
while (*str) {
h1 = Rand8[h1 ^ *str];
h2 = Rand8[h2 ^ *str];
str++;
}
/* h is in range 0..65535 */
h = ((HashIndexType)h1 << 8)|(HashIndexType)h2;
/* use division method to scale */
return h % HashTableSize
}
Размер хеш-таблицы должен быть достаточно большим, чтобы в ней оставалось
разумно большое число пустых мест. Как видно из таблицы 3.1, чем меньше
таблица, тем больше среднее время поиска ключа в ней. Хеш-таблицу можно
рассматривать как совокупность связанных списков. По мере того, как таблица
растет, увеличивается количество списков и, соответственно, среднее число
узлов в каждом списке уменьшается. Пусть количество элементов равно n.
Если размер таблицы равен 1, то таблица вырождается в один список длины
n. Если размер таблицы равен 2 и хеширование идеально, то нам придется
иметь дело с двумя списками по n/100 элементов в каждом. Это сильно
уменьшает длину списка, в котором нужно искать. Как мы видим в таблице
3.1, имеется значительная свободы в выборе длины таблицы.
| размер | время | размер | время | |
|---|---|---|---|---|
| 1 | 869 | 128 | 9 | |
| 2 | 432 | 256 | 6 | |
| 4 | 214 | 512 | 4 | |
| 8 | 106 | 1024 | 4 | |
| 16 | 54 | 2048 | 3 | |
| 32 | 28 | 4096 | 3 | |
| 64 | 15 | 8192 | 3 |