Два отличия LR(1)-разбора от LL(1)-разбора: во-первых, строится не левый вывод, а правый, во-вторых, он строится не с начала, а с конца. (Вывод в КС-грамматике называется правым, если на каждом шаге замене подвергается самый правый нетерминал.)
![]() 14.1.1. Доказать, что если слово, состоящее из терминалов,
выводимо, то оно имеет правый вывод.
14.1.1. Доказать, что если слово, состоящее из терминалов,
выводимо, то оно имеет правый вывод.![]()
Нам будет удобно смотреть на правый вывод << задом наперед>>. Определим понятие LR-процесса над словом A . В этом процессе, помимо A , будет участвовать и другое слово S , которое может содержать как терминалы, так и нетерминалы. Вначале слово S пусто. В ходе LR-процесса разрешены два вида действий:
Отметим, что LR-процесс не является детерминированным: в одной и той же ситуации могут быть разрешены разные действия.
Говорят, что LR-процесс на слове A успешно завершается, если слово A становится пустым, а в слове S остается единственный нетерминал -- начальный нетерминал грамматики.
![]() 14.1.2. Доказать, что для любого слова A (из терминалов)
успешно завершающийся LR-процесс существует тогда и только
тогда, когда слово A выводимо в грамматике. В ходе
доказательства установить взаимно однозначное соответствие между
правыми выводами и успешно завершающимися LR-процессами.
14.1.2. Доказать, что для любого слова A (из терминалов)
успешно завершающийся LR-процесс существует тогда и только
тогда, когда слово A выводимо в грамматике. В ходе
доказательства установить взаимно однозначное соответствие между
правыми выводами и успешно завершающимися LR-процессами.
Поскольку в ходе LR-процесса все изменения в слове S происходят с правого конца, слово S называют стеком LR-процесса.
Задача построения правого вывода для данного слова сводится, таким образом, к правильному выбору очередного шага LR-процесса. Нам нужно решить, будем ли мы делать сдвиг или свертку, и если свертку, то по какому правилу -- ведь подходящих правил может быть несколько. В LR(1)-алгоритме это решение принимается на основе S и первого символа слова A ; если используется только S , то говорят о LR(0)-алгоритме. (Точные определения смотри ниже.)
Пусть фиксирована грамматика, в которой из любого нетерминала можно вывести какое-либо слово из терминалов. (Это ограничение мы будет всегда предполагать выполненным.)
Пусть ![]() -- одно из правил грамматики (K
-- нетерминал, U -- слово из терминалов и нетерминалов).
Определим множество слов (из терминалов и нетерминалов),
называемое левым контекстом правила
-- одно из правил грамматики (K
-- нетерминал, U -- слово из терминалов и нетерминалов).
Определим множество слов (из терминалов и нетерминалов),
называемое левым контекстом правила ![]() .
(Обозначение:
.
(Обозначение: ![]() .) По определению в
него входят все слова, которые являются содержимым стека
непосредственно перед сверткой U в K в ходе некоторого
успешно завершающегося LR-процесса.
.) По определению в
него входят все слова, которые являются содержимым стека
непосредственно перед сверткой U в K в ходе некоторого
успешно завершающегося LR-процесса.![]()
![]() 14.1.3. Переформулировать это определение на языке правых
выводов.
14.1.3. Переформулировать это определение на языке правых
выводов.
![]() 14.1.4. Все слова из
14.1.4. Все слова из ![]() кончаются, очевидно,
на U. Доказать, что если у всех них этот конец U
отбросить, то полученное множество слов не зависит от того,
какое из правил для нетерминала K выбрано. (Это множество
обозначается
кончаются, очевидно,
на U. Доказать, что если у всех них этот конец U
отбросить, то полученное множество слов не зависит от того,
какое из правил для нетерминала K выбрано. (Это множество
обозначается ![]() .)
.)
![]() 14.1.5. Доказать, что в предыдущей фразе можно отбросить слова <<
самого правого>>:
14.1.5. Доказать, что в предыдущей фразе можно отбросить слова <<
самого правого>>: ![]() -- это все то, что может
появляться в правых выводах левее любого вхождения нетерминала
K.
-- это все то, что может
появляться в правых выводах левее любого вхождения нетерминала
K.
![]() 14.1.6. Построить грамматику, содержащую для каждого нетерминала K
исходной грамматики нетерминал
14.1.6. Построить грамматику, содержащую для каждого нетерминала K
исходной грамматики нетерминал
![]() ,причем следующее свойство должно выполняться для любого
нетерминала K исходной грамматики: в новой грамматике из
,причем следующее свойство должно выполняться для любого
нетерминала K исходной грамматики: в новой грамматике из
![]() выводимы все элементы
выводимы все элементы ![]() и только они.
и только они.
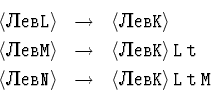 и аналогично поступим с другими правилами. Смысл новых правил
таков: пустое слово может появиться слева от P; если слово
X может появиться слева от K, то X может появиться
слева от L, XLt может появиться слева от M, XLtM
-- слева от N. Индукцией по длине правого вывода легко
проверить, что все, что может появиться слева от какого-то
нетерминала, появляется в соответствии с этими правилами.
и аналогично поступим с другими правилами. Смысл новых правил
таков: пустое слово может появиться слева от P; если слово
X может появиться слева от K, то X может появиться
слева от L, XLt может появиться слева от M, XLtM
-- слева от N. Индукцией по длине правого вывода легко
проверить, что все, что может появиться слева от какого-то
нетерминала, появляется в соответствии с этими правилами.
![]() 14.1.7. Почему в предыдущей задаче важно, что мы рассматриваем
только правые выводы?
14.1.7. Почему в предыдущей задаче важно, что мы рассматриваем
только правые выводы?
![]() 14.1.8. Для данной грамматики построить алгоритм, который по любому
слову выясняет, каким из множеств
14.1.8. Для данной грамматики построить алгоритм, который по любому
слову выясняет, каким из множеств ![]() оно принадлежит.
оно принадлежит.
(Замечание для знатоков. Существование такого алгоритма -- и даже конечного автомата, то есть индуктивного расширения с конечным числом значений, см. 1.3, -- вытекает из предыдущей задачи, так как построенная в ней грамматика имеет специальный вид: в правых частях всего один нетерминал, причем он стоит у левого края. Тем не менее мы приведем явное построение.)
Решение. Будем называть ситуацией данной грамматики одно из ее правил, в правой части которого отмечена одна из позиций (до первой буквы, между первой и второй буквой,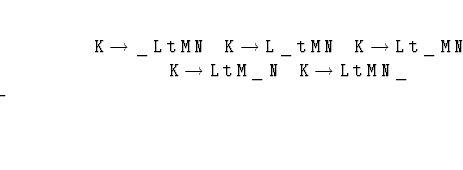 (позиция указывается знаком подчеркивания).
(позиция указывается знаком подчеркивания).
Будем говорить, что слово S согласовано с ситуацией
![]() , если S кончается на U, то есть
, если S кончается на U, то есть
![]() при некотором T, и, кроме того, T
принадлежит
при некотором T, и, кроме того, T
принадлежит ![]() . (Смысл этого определения примерно
таков: в стеке S подготовлена часть U для будущей
свертки UV в K.) В этих терминах
. (Смысл этого определения примерно
таков: в стеке S подготовлена часть U для будущей
свертки UV в K.) В этих терминах
![]() -- это множество всех слов,
согласованных с ситуацией
-- это множество всех слов,
согласованных с ситуацией ![]() , а
, а
![]() -- это множество всех слов, согласованных с
ситуацией
-- это множество всех слов, согласованных с
ситуацией ![]() (где
(где ![]() --
любое правило для нетерминала K).
--
любое правило для нетерминала K).
Эквивалентное определение в терминах LR-процесса: S
согласовано с ситуацией ![]() , если
существует успешный LR-процесс, в котором события развиваются
так:
, если
существует успешный LR-процесс, в котором события развиваются
так:
![]() 14.1.9. Доказать эквивалентность этих определений.
14.1.9. Доказать эквивалентность этих определений.
Наша цель -- построение алгоритма, распознающего
принадлежность произвольного слова к ![]() .Рассмотрим функцию, сопоставляющую с каждым словом S (из
терминалов и нетерминалов) множество всех согласованных с ним
ситуаций. Это множество назовем состоянием, соответствующим
слову S.
Будем обозначать его
.Рассмотрим функцию, сопоставляющую с каждым словом S (из
терминалов и нетерминалов) множество всех согласованных с ним
ситуаций. Это множество назовем состоянием, соответствующим
слову S.
Будем обозначать его ![]() . Достаточно
показать, что функция
. Достаточно
показать, что функция ![]() индуктивна, то есть что
значение
индуктивна, то есть что
значение ![]() , где J -- терминал или
нетерминал, может быть вычислено, если известно
, где J -- терминал или
нетерминал, может быть вычислено, если известно
![]() и символ J. (Мы видели ранее, как
принадлежность к
и символ J. (Мы видели ранее, как
принадлежность к ![]() выражается в терминах этой
функции.) Значение
выражается в терминах этой
функции.) Значение ![]() вычисляется по таким правилам:
вычисляется по таким правилам:
(1) Если слово S согласовано с ситуацией, причем слово V начинается на букву J, то есть
, то SJ согласовано с ситуацией
.
Это правило полностью определяет все ситуации с непустой
левой половиной (то есть не начинающиеся с подчеркивания),
согласованные с SJ. Осталось определить, для каких
нетерминалов K слово SJ принадлежит ![]() .Это делается по двум правилам:
.Это делается по двум правилам:
(2) Если ситуациясогласована с SJ (согласно правилу (1)), а V начинается на нетерминал К, то SJ принадлежит
.
(3) Если SJ входит в
для некоторого L, причем
-- правило грамматики и V начинается на нетерминал K, то SJ принадлежит
Заметим, что правило (3) можно рассматривать как аналог
правила (2): в указанных в (3) предположениях ситуация
![]() согласована с SJ, а V начинается на
нетерминал K.
согласована с SJ, а V начинается на
нетерминал K.
Корректность этих правил в общем-то очевидна, если
хорошенько подумать. Единственное, что требует некоторых
пояснений -- это то, почему с помощью правил (2) и (3)
обнаружатся все терминалы K, для которых SJ
принадлежит ![]() . Попытаемся это объяснить.
Рассмотрим правый вывод, в котором SJ стоит слева от K.
Откуда мог взяться в нем нетерминал K? Если правило, которое
его породило, породило также и конец слова SJ, то
принадлежность SJ к
. Попытаемся это объяснить.
Рассмотрим правый вывод, в котором SJ стоит слева от K.
Откуда мог взяться в нем нетерминал K? Если правило, которое
его породило, породило также и конец слова SJ, то
принадлежность SJ к ![]() будет обнаружена по
правилу (2). Если же K было первой буквой слова,
порожденного каким-то другим нетерминалом L, то -- благодаря
правилу (3) -- достаточно установить принадлежность SJ к
будет обнаружена по
правилу (2). Если же K было первой буквой слова,
порожденного каким-то другим нетерминалом L, то -- благодаря
правилу (3) -- достаточно установить принадлежность SJ к
![]() . Осталось применить те же рассуждения к L и
так далее.
. Осталось применить те же рассуждения к L и
так далее.
В терминах LR-процесса то же самое можно сказать так. Сначала нетерминал K может участвовать в нескольких свертках, не затрагивающих SJ (они соответствуют применению правила (3)), но затем он обязан подвергнуться свертке, затрагивающей SJ (что соответствует применению правила (2)).
Осталось выяснить, какие ситуации согласованы с пустым
словом, то есть для каких нетерминалов K пустое слово
принадлежит ![]() . Это определяется по следующим
правилам:
. Это определяется по следующим
правилам:
(1) начальный нетерминал таков;(2) если K таков и
-- правило грамматики, причем слово V начинается с нетерминала L, то и L таков.
![]() 14.1.10. Проделать описанный анализ для грамматики
14.1.10. Проделать описанный анализ для грамматики
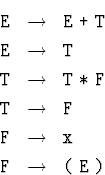 (задающей тот же язык, что и
грамматика примера 3, с.
(задающей тот же язык, что и
грамматика примера 3, с. ![[*]](cross_ref_motif.gif) ).
Решение. Множества Сост(S) для различных S
приведены в таблице.
).
Решение. Множества Сост(S) для различных S
приведены в таблице.
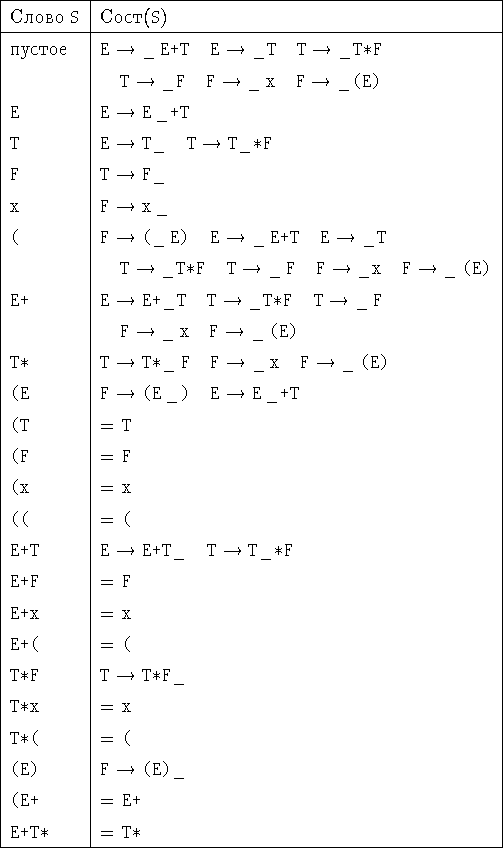
Правило определения ![]() , если известны
, если известны
![]() и J (здесь S -- слово из терминалов и
нетерминалов, J -- терминал или нетерминал), таково:
и J (здесь S -- слово из терминалов и
нетерминалов, J -- терминал или нетерминал), таково:
надо найтив правой колонке, взять соответствующее ему слово T в левой колонке, приписать к нему J и взять множество, стоящее напротив слова ТJ (если слово ТJ в таблице отсутствует, то
пусто).