Мы можем искать не конкретное слово, а подслова заданного вида. Например, можно искать слова вида a?b, где вместо ? может стоять любая буква (иными словами, нас интересует буква b на расстоянии 2 после буквы a).
![]() 10.7.1. Указать конечный автомат, проверяющий, есть ли во
входном слове фрагмент вида a?b.
10.7.1. Указать конечный автомат, проверяющий, есть ли во
входном слове фрагмент вида a?b.

1cm
Таблица переходов автомата:
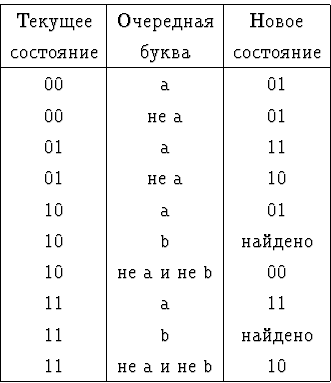
![]()
Другой стандартный знак в образце -- это звездочка (*), на место которой может быть подставлено любое слово. Например, образец ab*cd означает, что мы ищем подслово ab, за которым следует что угодно, а затем (на любом расстоянии) идет cd.
![]() 10.7.2. Указать конечный автомат, проверяющий, есть ли во входном
слове образец ab*cd (в описанном только что смысле).
10.7.2. Указать конечный автомат, проверяющий, есть ли во входном
слове образец ab*cd (в описанном только что смысле).
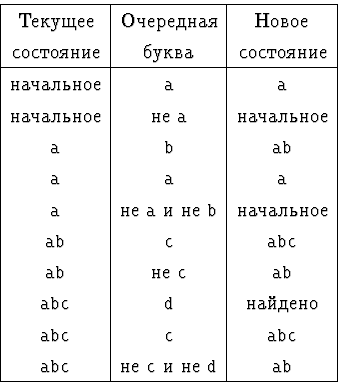
![]()
Еще один вид поиска -- это поиск любого из слов некоторого списка.
![]() 10.7.3. Дан список слов
10.7.3. Дан список слов ![]() и слово Y . Определить,
входит ли хотя бы одно из слов Xi в слово Y (как подслово).
Количество действий не должно превосходить константы, умноженной
на суммарную длину всех слов (из списка и того, в котором
происходит поиск).
и слово Y . Определить,
входит ли хотя бы одно из слов Xi в слово Y (как подслово).
Количество действий не должно превосходить константы, умноженной
на суммарную длину всех слов (из списка и того, в котором
происходит поиск).
Посмотрим на дело с другой стороны. Каждому образцу из списка соответствует конечный автомат с некоторым множеством состояний. Эти автоматы можно объединить в один, множеством состояний которого будет произведение множеств состояний всех тех автоматов. Это -- очень большое множество. Однако на самом деле большинство его элементов недоступны (не могут появиться при чтении входного слова) и за счет этого получается экономия. Примерно эту идею (но в измененном виде) мы и будем использовать.
Вспомним алгоритм Кнута-Морриса-Пратта. В нем, читая входное слово, мы хранили наибольшее начало образца, являющееся концом прочитанной части. Теперь нам следует хранить для каждого из образцов наибольшее его начало, являющееся концом прочитанной части. Решающим оказывается такое замечание: достаточно хранить самое длинное из них -- все остальные по нему восстанавливаются (как наибольшие начала образцов, являющиеся его концами).
Склеим все образцы в дерево, объединив их совпадающие
начальные участки. Например, набору образцов
![]() соответствует дерево
соответствует дерево
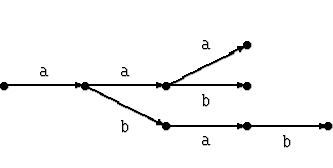 Формально говоря, вершинами дерева являются все начала всех
образцов, а сыновья вершины получаются приписыванием буквы.
Формально говоря, вершинами дерева являются все начала всех
образцов, а сыновья вершины получаются приписыванием буквы.
Читая входное слово, мы двигаемся по этому дереву: текущая вершина -- это наибольшая (самая правая) из вершин, являющихся концом прочитанной части (= наибольший конец прочитанной части, являющийся началом одного из образцов).
Определим функцию l , аргументами и значениями которой являются вершины дерева. Именно, l(P) = наибольшая вершина дерева, являющаяся концом P . (Напомним, вершины дерева -- это слова.) Нам понадобится такое утверждение:
![]() 10.7.4. Пусть P -- вершина дерева. Докажите, что множество всех
вершин, являющихся концами P , равно
10.7.4. Пусть P -- вершина дерева. Докажите, что множество всех
вершин, являющихся концами P , равно ![]()
Теперь ясно, что нужно делать, находясь в вершине P и читая букву z входного слова. Надо просматривать последовательно вершины P , l(P) , l(l(P)) ,..., пока не обнаружится такая, из которой выходит стрелка с буквой z. Та вершина, в которую эта стрелка ведет, и будет нашим следующим положением.
Остается понять, как для каждой вершины дерева вычислить
указатель на значение функции l в этой вершине. Это делается как
раньше, при этом значения l для более коротких слов используются
при вычислении очередного значения функции l . Это означает, что
вершины дерева следует просматривать в порядке возрастания их
длины. Нетрудно понять, что все это можно уложить в требуемое
число действий (хотя константа зависит от числа букв в
алфавите). Относящиеся к этому подробности см. в главе 9.![]()
Можно поинтересоваться, какие свойства слов распознаются с помощью конечных автоматов. Оказывается, что существует просто описываемый класс образцов, задающий все такие свойства -- класс регулярных выражений.
Определение. Пусть фиксирован конечный алфавит
Множества, соответствующие регулярным выражениям, называются
регулярными. Вот несколько примеров:

![]() 10.7.5. Написать регулярное выражение, которому соответствует множество
всех слов из букв a и b, в которых число букв a
четно.
10.7.5. Написать регулярное выражение, которому соответствует множество
всех слов из букв a и b, в которых число букв a
четно.
![]() 10.7.6. Написать регулярное выражение, которое задает множество
всех слов из букв
10.7.6. Написать регулярное выражение, которое задает множество
всех слов из букв ![]() , в которых слово bac
является подсловом.
, в которых слово bac
является подсловом.
Теперь задачу о поиске образца в слове можно переформулировать так: проверить, принадлежит ли слово множеству, соответствующему данному регулярному выражению.
![]() 10.7.7. Какие выражения соответствуют образцам a?b и ab*cd,
рассмотренным ранее? (В образце символ * используется не в том
смысле, что в регулярных выражениях!) Предполагается, что алфавит
содержит буквы
10.7.7. Какие выражения соответствуют образцам a?b и ab*cd,
рассмотренным ранее? (В образце символ * используется не в том
смысле, что в регулярных выражениях!) Предполагается, что алфавит
содержит буквы ![]() .
.
![]() 10.7.8. Доказать, что для всякого регулярного выражения можно
построить конечный автомат, который распознает соответствующее
этому выражению множество слов.
10.7.8. Доказать, что для всякого регулярного выражения можно
построить конечный автомат, который распознает соответствующее
этому выражению множество слов.
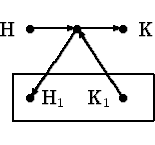
Будем двигаться различными способами из Н в К, читая буквы по дороге (на тех стрелках, где они есть). Каждому пути из Н в К, таким образом, соответствует некоторое слово. А источнику в целом соответствует множество слов -- тех слов, которые можно прочесть на путях из Н в К.
Замечание. Если нарисовать состояния конечного автомата в виде точек, а переходы при чтении букв изобразить в виде стрелок, то станет ясно, что конечный автомат -- это частный случай источника. (С дополнительными требованиями: (а) на всех стрелках есть буквы, и (б) для любой точки на выходящих из нее стрелках каждая буква встречается ровно один раз.)Мы будем строить конечный автомат по регулярному выражению в два приема. Сначала мы построим источник, которому соответствует то же самое множество слов. Затем для произвольного источника построим автомат, который проверяет, принадлежит ли слово соответствующему множеству.
![]() 10.7.9. По регулярному выражению построить источник, задающий то же
множество.
10.7.9. По регулярному выражению построить источник, задающий то же
множество.
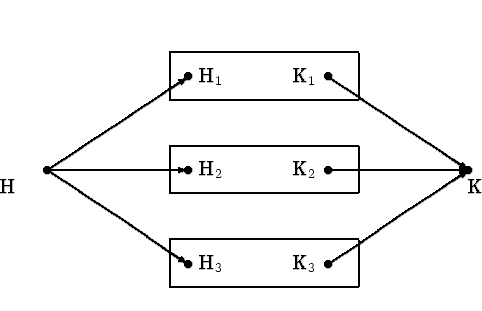 Нарисована картинка для объединения трех множеств,
прямоугольники -- это источники, им соответствующие; указаны
начальные и конечные вершины. На новых стрелках (их 6 ) букв не
написано.
Нарисована картинка для объединения трех множеств,
прямоугольники -- это источники, им соответствующие; указаны
начальные и конечные вершины. На новых стрелках (их 6 ) букв не
написано.
Конкатенации соответствует картинка
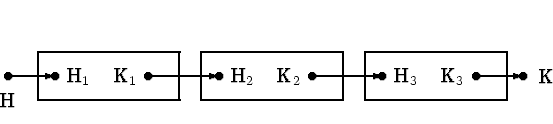 Наконец, итерации соответствует картинка
Наконец, итерации соответствует картинка
![]()
![]() 10.7.10. Дан источник. Построить конечный автомат, проверяющий,
принадлежит ли входное слово соответствующему множеству
(то есть можно ли прочесть это слово, идя из Н в К).
10.7.10. Дан источник. Построить конечный автомат, проверяющий,
принадлежит ли входное слово соответствующему множеству
(то есть можно ли прочесть это слово, идя из Н в К).
Оказывается, что регулярные выражения, автоматы и источники распознают одни и те же множества. Чтобы убедиться в этом, нам осталось решить такую задачу:
![]() 10.7.11. Дан источник. Построить регулярное выражение, задающее то
же множество, что и этот источник.
10.7.11. Дан источник. Построить регулярное выражение, задающее то
же множество, что и этот источник.
Индукцией по s будем доказывать регулярность всех множеств Di,j,s при всех i и j . При s=0 это очевидно (промежуточные вершины запрещены, поэтому каждое из множеств состоит только из букв).
Из чего состоит множество Di,j,s+1 ? Отметим на пути
моменты, в которых он заходит в (s+1) -ую вершину. При этом путь
разбивается на части, каждая из которых уже не заходит в нее.
Поэтому легко сообразить, что
![]() (вольность записи: мы используем для операций над множествами
обозначения как для регулярных выражений). Остается
воспользоваться предположением индукции.
(вольность записи: мы используем для операций над множествами
обозначения как для регулярных выражений). Остается
воспользоваться предположением индукции.![]()
![]()
![]() 10.7.12. Где еще используется то же самое рассуждение?
10.7.12. Где еще используется то же самое рассуждение?
![]() 10.7.13. Доказать, что класс множеств, задаваемых регулярными
выражениями, не изменился бы, если бы мы разрешили использовать
не только объединение, но и отрицание (а следовательно, и
пересечение -- оно выражается через объединение и отрицание).
10.7.13. Доказать, что класс множеств, задаваемых регулярными
выражениями, не изменился бы, если бы мы разрешили использовать
не только объединение, но и отрицание (а следовательно, и
пересечение -- оно выражается через объединение и отрицание).
Замечание. На практике важную роль играет число состояний автомата. Оказывается, что тут все не так просто, и переход от источника к автомату требует экспоненциального роста числа состояний. Подробное рассмотрение связанных с этим теоретических и практических вопросов -- дело особое (см. книгу Ахо, Ульмана и Сети о компиляторах).