![]() 10.2.1. Можно ли в предыдущих рассуждениях заменить слово
abcd на произвольное слово?
10.2.1. Можно ли в предыдущих рассуждениях заменить слово
abcd на произвольное слово?
Вот картинка, поясняющая сказанное:
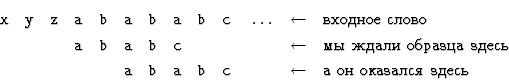 Таким образом, к моменту
Таким образом, к моменту
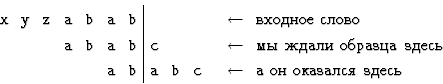 есть два возможных положения образца, каждое из которых подлежит
проверке. Тем не менее по-прежнему возможен конечный автомат,
читающий входное слово буква за буквой и переходящий из
состояния в состояние в зависимости от прочитанных букв.
есть два возможных положения образца, каждое из которых подлежит
проверке. Тем не менее по-прежнему возможен конечный автомат,
читающий входное слово буква за буквой и переходящий из
состояния в состояние в зависимости от прочитанных букв.![]()
![]() 10.2.2. Указать состояния соответствующего автомата и таблицу
перехода (новое состояние в зависимости от старого и читаемой
буквы).
10.2.2. Указать состояния соответствующего автомата и таблицу
перехода (новое состояние в зависимости от старого и читаемой
буквы).
 Для проверки посмотрим, к примеру, на вторую снизу строку. Если
прочитанная часть кончалась на abab, а затем появилась буква
a, то теперь прочитанная часть кончается на ababa.
Наибольшее начало образца (ababc), являющееся ее концом --
это aba.
Для проверки посмотрим, к примеру, на вторую снизу строку. Если
прочитанная часть кончалась на abab, а затем появилась буква
a, то теперь прочитанная часть кончается на ababa.
Наибольшее начало образца (ababc), являющееся ее концом --
это aba.
Философский вопрос: мы говорили, что трудность состоит в том, что есть несколько возможных положений образца, каждое из которых может оказаться истинным. Им соответствуют несколько начал образца, являющихся концами входного слова. Но конечный автомат помнит лишь самое длинное из них. Как же остальные?
Философский ответ. Дело в том, что самое длинное из них определяет все остальные -- это его концы, одновременно являющиеся его началами.
Не составляет труда для любого конкретного образца написать программу, осуществляющую поиск этого образца описанным способом. Однако хотелось бы написать программу, которая ищет произвольный образец в произвольном слове. Это можно делать в два этапа: сначала по образцу строится таблица переходов конечного автомата, а затем читается входное слово и состояние преобразуется в соответствии с этой таблицей. Подобный метод часто используется для более сложных задач поиска (см. далее), но для поиска подслова существует более простой и эффективный алгоритм, называемый алгоритмом Кнута-Морриса-Пратта. (Ранее сходные идеи были предложены Ю.В. Матиясевичем) Но прежде нам понадобятся некоторые вспомогательные утверждения.