 |
|

Поиск в строках, массивах, последовательностях:
Нечеткий поиск.
k несовпадений – Ландау-Вишкин
В алгоритме k несовпадений Ландау-Вишкина (1985, 1986a) строка текста анализируется с помощью 2-мерной таблицы несовпадений образца (pattern mismatch) pm[1…m-1, 1…2k+1], генерируемой на стадии предварительной обработки образца. Вычисление этой таблицы будет рассмотрено чуть ниже. Сначала мы рассмотрим стадию анализа текста.
При анализе текста используется двумерный массив tm[0…n-m, 1…k+1], содержащий информацию о несовпадениях текста с образцом. По завершении анализа в его i-й строке содержатся позиции в x первых k+1 несовпадений между строками x(1, m) и y(i+1, i+m). Таким образом, если tm[i, v] = s, то yi+s =/=xs, и это v-е несовпадение между x(1, m) и y(i+1, i+m), считая слева направо. Если число c несовпадений x с подстрокой y(i+1, i+m) меньше k+1, то, начиная с c+1, элементы i-й строки равны значению по умолчанию m+1, то есть:
tm[i, c+1] = tm[i, c+2] = … = tm[i, k+1] = m+1
Обратите внимание: если tm[i, k+1] = m+1, то подстрока y(i+1, i+m) отличается от образца x не более, чем на k символов, и, таким образом, является решением задачи. Это иллюстрируется следующим примером. Рассмотрим случай, когда x = tram, y = thetrippedtrap, а k = 2. Из приведенной ниже таблицы текстовых несовпадений можно видеть, что в тексте найдены вхождения образца с точностью до двух символов, начинающиеся с y4 и y11, а именно, подстроки trip и trap.
|
|
1 |
2 |
3 |
|
0 |
2 |
3 |
4 |
|
1 |
1 |
2 |
3 |
|
2 |
1 |
2 |
3 |
|
3 |
3 |
4 |
5 |
|
4 |
1 |
2 |
3 |
|
5 |
1 |
2 |
3 |
|
6 |
1 |
2 |
3 |
|
7 |
1 |
2 |
3 |
|
8 |
1 |
2 |
3 |
|
9 |
1 |
2 |
3 |
|
10 |
4 |
5 |
5 |
Алгоритм анализа текста приведен на рисунке 25. Образец сканируется в цикле for параллельно с текстом слева на права по одному символу за раз. На итерации i с образцом сравнивается подстрока y(i+1, i+m). Самая правая позиция в тексте, достигнутая за предыдущие итерации, задается значением j, то есть j является максимальным из чисел r+tm[r, k + 1], где 0 < r < i. Если i < j, вызывается процедура merge, которая находит несовпадения между x(1, j - i) и y(i+1,j) и устанавливает b равным найденному числу. Если оно не превышает k, вызывается процедура extend. Она сканирует текст впереди от y[j + 1], пока либо не будет найдено k + 1 несовпадений, либо не будет достигнуто y[i+m] с не больше чем k несовпадениями, то есть найдено вхождение образца, начинающееся с y[i+1].
Устройство extend довольно очевидно, текст процедуры приведен на рисунке 26. Сравниваются пары символов из подстрок y(j + 1, i + m) и x(j - i + 1, m), и в случае несовпадения b увеличивается и таблица текстовых несовпадений обновляется.
- инициализация
tm[0 ... n - m, 1 ... k + 1] = m + 1
r = 0
j = 0
- сканирование текста
for i = 0 to n - m
b = 0
if i < J
merge(I, R, J, B)
IF B < K + 1
R=I
extend(I, J, B)
Рис. 25: Сопоставление строк по Ландау-Вишкину
extend(i, j, b)
while (b < K + 1) AND (J - I < M)
J = J + 1
IF Yj =/=xj-i
b = b + 1
tm[i, b] = j - i
Рис. 26: Процедура extend
Теперь исследуем работу процедуры merge. Как упоминалось ранее, эта процедура находит несовпадения между x(1, j-1) и y(i+1, j) и устанавливает b равным найденному числу. Таким образом, merge оценивает tm[i, 1 ... b] для b < k+1, и конечно при этом используется полученная ранее информация. Во-первых, вспомним, что строка r таблицы несовпадений рапортует о несовпадениях, полученных при совмещении начала образца и yr+1, а r+tm[r, k+1] содержит текущий номер самой правой из проверенных на настоящий момент позиций текста. Поэтому несовпадения справа от yi, информация о которых содержится в r-й строке tm, неглупо было бы учитывать при сравнении образца с текстом, начинающимся с yi+1. Подходящими значениями из таблицы несовпадений являются, таким образом, tm[r, q ... k+1], где q – это наименьшее из целых чисел, для которых r+tm[r, q] > i. Однако, следует учитывать тот факт, что эти несовпадения соответствуют началу образца, выравниваемому с yr+1, в то время как текущая позиция образца выровнена с yi+1 – разница в i - r мест.
Вторым источником используемой в merge информации является, таким образом, предварительно вычисленная таблица pm несовпадений, дающая позиции несовпадения образца с самим собой при различных сдвигах. Строка i массива pm[1…m-1, 1 ... 2k+1] содержит позиции внутри x первых 2k+1 несовпадений между подстроками x(1, m-i) и x(i+1, m), то есть перекрывающимися порциями двух копий шаблона для соответствующего сдвига i. Таким образом, если pm[i, u] = s, то xi+s =/=xs, и это u-е несовпадение между x(1, m-i) и x(i+1, m) слева направо. Если число c несовпадений между этими строками меньше 2k+1, то, начиная с c+1, элементы i-й строки равны m+1, значению по умолчанию, то есть:
pm[i, c+1] = pm[i, c+2] = … = pm[i, 2k+1] = m+1
Таким образом, для merge интерес представляет строка i - r таблицы несовпадений, причем используются значения pm[i-r, 1…t], где t – самое правое несовпадение в pm[i-r, 1…2k+1], такое, что pm[i-r, t] < j-i+1, так как требуются только несовпадения в подстроке x(1, j-i).
Чтобы понять, как упомянутая информация может использоваться в процедуре merge, рассмотрим в тексте позицию p, находящуюся в соответствующем диапазоне, i+1 < p < j. Позиция p может удовлетворять или не удовлетворять любому из приведенных ниже условий.
A: когда символы x1 и yr+1 совмещены, позиция p в тексте соответствует предварительно выявленному несовпадению между образцом и текстом, то есть yp =/=xp-r, и это несовпадение номер v, где q < v < k+1, то есть p - r = tm[r, v].
B: для двух копий образца, со сдвигом относительно друг друга i - r, совмещенных с текстом так, что их начальные символы лежат, соответственно, над yr+1 и yi+1, позиция p соответствует несовпадению между двумя шаблонами, то есть xp-r =/=xp-i. Это u-е несовпадение при этом сдвиге, где 1 < u < t, то есть p-i = pm[i-r, u].
Вспомним, что нас интересует, совпадает ли символ текста в позиции p с соответствующими символом образца, когда x1 совмещен с yi+1, то есть верно ли, что yp = xp-i. Рассмотрим этот вопрос при разных комбинациях указанных выше условий.
Случай 1: не выполняется ни условие A, ни условие B. То есть, yp = xp-r и xp-r = xp-i, откуда yp = xp-i. Нет необходимости сравнивать символ текста с символом шаблона, так как ясно, что в этой позиции они совпадают.
Случай 2: выполняется только одно из условий, то есть либо условие A, либо условие B, но не оба сразу. В любом случае yp =/=xp-i. Если лишь условие A истинно, то yp =/=xp-r и xp-r = xp-i, откуда yp =/=xp-i. С другой стороны, если выполнено только условие B, то yp = xp-r и xp-r =/=xp-i, и опять, yp =/=xp-i. Как и в предыдущем случае, нет необходимости сравнивать символ текста с символом шаблона, так как известно, что они не совпадают.
Случай 3: выполняются оба условия – и условие A, и условие B. В этом случае мы ничего не можем сказать о том, совпадают ли символы yp и xp-i, поэтому их надо сравнить.
В случае 2, или если в случае 3 выявлено несовпадение символов, необходимо увеличить количество несовпадений символов b на единицу и обновить tm[i, b] в процедуре merge.
Теперь опишем процедуру merge, представленную на рисунке 27. Как упоминалось ранее, соответствующими значениями таблицы для merge являются tm[i-r, 1…t] и tm[r, q…k+1]. Переменные u и v в начале устанавливаются равными индексам первых элементов этих двух векторов, соответственно, и последовательно увеличиваются соответственно векторным компонентам.
Условия окончания работы процедуры следующие. Во первых, если b = k+1, то для случая, когда шаблон расположен относительно текста так, что x1 совмещен с yi+1, обнаружено k+1 несовпадение, поэтому из процедуры можно выйти. Во вторых, вспомним, что самая правая из интересующих нас позиций в merge, а именно, j, равна r+tm[r, k+1], если v = k+2, поэтому tm[r, k+1] будет уже использовано для предыдущего значения v, а именно, v = k+1, и поэтому позиция j должна быть пропущена. Следовательно, в этом случае также можно выйти из процедуры. Наконец, процедуру можно прервать, если i+pm[i-r, u] > j и tm[r, v] = m+1. Если выполняется вторая часть этого условия, то r+tm[r, v] равняется j, и соответствует суммам для последующих значений v вплоть до k+1. В этом случае процедура может быть прервана, если выполняется также первая часть приведенного условия, так как она указывает, что позиция текста j фактически пропущена.
Остается показать, что число позиций несовпадений в таблице несовпадений шаблона достаточно для того, чтобы merge нашла все, или, если их больше k+1, первые k+1 несовпадений для y(i+1, j). Это можно показать следующим образом. Условие A выполняется не больше чем для k+1 позиции текста в диапазоне [i+1, j]. Условие B выполняется для некоторого неизвестного числа позиций в этом же интервале. Строка i-r в таблице несовпадений шаблона, tm[i-r, 1 ... 2k+1], содержит не больше чем 2k+1 позиций несовпадений между двумя копиями шаблона, с соответствующим сдвигом i-r. Если pm[i-r, 2k+1] > j - i, то таблица содержит все позиции несовпадения шаблона самим с собой, у которых условие B выполняется для позиций текста в интервале [i+1, j]. С другой стороны, если pm[i-r, 2k+1] < j-i, то таблица может дать 2k+1 позиций текста в диапазоне [i+1, j-1], для которых выполняется условие B. Поскольку j = r+tm[r, k+1], в диапазоне [i+1, j-1] имеется до k позиций текста, для которых выполняется условие A. Таким образом, в худшем случае может быть k позиций, для которых имеет место случай 3, и которые требуется сравнить напрямую. Остается по крайней мере k+1 позиций, удовлетворяющих условию B, но не условию A (случай 2), что является достаточным, чтобы заключить, что для данного положения шаблона относительно текста имеется не меньше k+1 несовпадений между текстом и шаблоном.
Теперь исследуем затраты времени на анализ текста. Если исключить вызовы процедур merge и extend, каждая из n-m+1 итераций цикла анализа текста выполняется за фиксированное время, что дает в общей сложности время O(n). Общее число операций, выполняемых процедурой extend во время вызовов равно O(n), так как она проверяет каждый символ текста не больше одного раза. Процедура merge при каждом вызове обрабатывает вектора pm[i-r, 1 ... 2k+1] и tm[r, 1…k+1], которые в сумме имеют 3k+2 элементов. Время работы merge можно рассчитать, соотнеся операции с фиксированным временем с каждым из этих входов, что дает время счета для каждого вызова, равное O(k). Таким образом, можно видеть, что общее время анализа текста составляет O(nk).
merge(i, r, j, b)
u = 1
v = q
while (b < K + 1) AND (V < K + 2)
AND (I + PM[I - R, U] < j or tm[r, v] =/=m + 1)
if i + pm[i - r, u] > r + tm[r, v]
- Случай 2, условие A
b = b + 1
tm[i, b] = tm[r, v] - (i - r)
v = v + 1
else if i + pm[i - r, u] < R + TM[R, V]
- СЛУЧАЙ 2, УСЛОВИЕ B
B = B + 1
TM[I, B] = PM[I - R, U]
U = U + 1
else
- I + PM[I - R, U] = R + TM[R, V]
- СЛУЧАЙ 3
IF Xpm[i-r,u] =/=yi+pm[i-r,u]
b = b + 1
tm[i, b] = pm[i - r, u]
u = u +1
v = v + 1
Рисунок 27: Процедура merge Ландау-Вишкина
- инициализацияr = 2l-1 j = 2l-1 - вычисление строк pm в множестве l for i = 2l-1 to 2l - 1 b = 0 if i < J merge(I, R, J, B) IF
r = i extend(i, j, b)
Рисунок 28: Предварительная обработка образца Ландау-Вишкина
Теперь осталось только обратиться к вычислению таблицы несовпадений шаблона на стадии предварительных вычислений. Не теряя общности, можно предположить, что m является некоторой степенью 2. В алгоритме предварительной обработки используется разбиение множества {1, 2, ... , m-1} из m-1 строк pm на следующие log2m подмножеств:
{1}, {2, 3}, {4, 5, 6, 7}, ... , {m/2, ... , m-1}
Алгоритм состоит из log2m этапов. На этапе s, где 1 < s < log2m, вычисляются строки pm в множестве s, где множество s – это {2s-1, ... , 2s-1}.
Метод, используемый для вычисления этой таблицы, основан на методе, используемом на стадии анализа текста, алгоритм для этапа s приведен на рисунке 28. На стадии s входами для алгоритма анализа образца являются подстроки образца x(1, m-2s-1) и x(2s-1+1, m), которые трактуются здесь, соответственно, как образец и текст, и массив pm[1…2s-1-1, 1…min{2log(m)-s4k+1, m-2s-1}], содержащий выходы предыдущих l - 1 стадий. (Число элементов в строках подмассива будет объяснено позже). Выходы стадии s вводятся в. За исключением стадии log2m, на которой находят до 2k+1 несовпадений, на стадии s для каждой строки pm требуется найти до min{2log(m)-s2k+1, m-2s} несовпадений, а не до k+1, как в алгоритме анализа текста.
Используя аргументы, аналогичные применявшимся при проверке корректности процедуры merge, можно показать, что для нахождения требуемого количества несовпадений на стадии s требуется min{2log(m)-s4k+1, m-2s} позиций, для которых выполняется условие B, и в особом случае, а именно, на стадии log2m, требуется 4k + 1 таких позиций.
На каждой стадии s из log2m стадий анализа шаблона цикл for производит 2s-1 итераций (2s-1 < i < 2s - 1). Если не считать время работы процедур merge и extend, каждая итерация требует фиксированного времени. Для всех итераций на шаге s процедуре extend требуется время O(m). Ранее было показано, что время работы merge пропорционально числу искомых несовпадений. Таким образом, каждый вызов merge занимает время ![]() , что равно
, что равно ![]() . Таким образом, общее время для стадии s равно
. Таким образом, общее время для стадии s равно 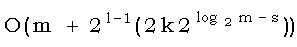 =O(km). Проведя суммирование по всем стадиям, получаем общее время счета
=O(km). Проведя суммирование по всем стадиям, получаем общее время счета 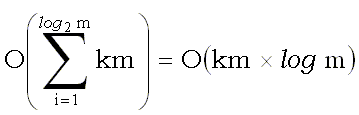 . Таким образом, общие затраты времени, включающие предварительную обработку шаблона и анализ текста, равны O(k(n + m log m)).
. Таким образом, общие затраты времени, включающие предварительную обработку шаблона и анализ текста, равны O(k(n + m log m)).
 Вверх по странице, к оглавлению и навигации.
Вверх по странице, к оглавлению и навигации.