3. ПРИМЕНЕНИЕ МЕТОДОВ СТРУКТУРНОГО АНАЛИЗА ПРИ РАЗРАБОТКЕ ФУНКЦИОНАЛЬНО-УПРАВЛЯЮЩЕЙ МОДЕЛИ ТРЕБОВАНИЙ
3.1. Общая стратегия построения функционально-управляющей моделиНа фазе анализа требований, содержащихся в документе ⌠Требования к системе■ (или аналогичном ему по содержанию) необходимо содержательно и полно описать ⌠внешнее функционирование■ ПО с привлечением, если потребуется, дополнительных сведений о предметной области проекта. Заметим, что в случае каких либо затруднений используются консультации с заказчиком системы и, если есть, документы предыдущих аналогичных разработок. Результатом фазы анализа требований является создание абстрактной функционально-информационной модели будущего ПО в виде различных диаграмм. В основном следуя [ 7 ], приведем примерную последовательность шагов, вполне отражающих основное направление процесса строительства функционально-информационной модели системы:
- выделить в требованиях пользователя несколько главных функциональных групп;
- идентифицировать внешние сущности (такие как другие технические системы, панель управления, человек-оператор и т.д.) с которыми проектируемой системе требуется взаимодействовать;
- идентифицировать главные информационные потоки, которые должны циркулировать между системой и внешними сущностями;
- начать конструирование диаграммы высокого уровня, представляя главные функциональные группы в виде процессов, внешние сущности в виде терминаторов, и главные информационные потоки в виде потоков данных;
- изучить полученную диаграмму и сделать необходимые ее изменения, отвечая себе на следующие вопросы:
- правильно ли модель системы отграничена от внешнего мира? Не могут ли некоторые терминаторы в действительности быть частями системы, а некоторые процессы - терминаторами?
- хорошо ли процессы отражают точку зрения потребителя на системные требования? Не может ли функциональное переразбиение процессов сделать требования яснее?
- идут ли потоки данных из корректных мест? Вполне ли естественно для процессов производить производить указанные выходы из указанных входов? Не может ли диаграмма стать яснее при перегруппировке потоков данных?
- выделить контекстную диаграмму, переведя на нее все терминаторы и, если это возможно и естественно, сжимая потоки данных в небольшое количество групп, соединяющих терминаторы с единственным процессом (который, вообще говоря, не несет особой смысловой нагрузки, а просто унифицирует графическое представление метода);
- из оставшихся процессов (или наиболее крупных их групп; последнее применимо, если число процессов превосходит рекомендуемое для одной диаграммы число в 5-7 основных ее элементов) сформировать первый уровень DCFD;
- решить на основе анализа требований, имеются ли какие-либо режимы или условия работы системы, когда какие-либо из процессов требуют деактивации. Если таковые есть, то идентифицировать сигналы, представляющие эти режимы или условия, и представить их в виде потоков управления и соответствующей STD. Дальнейшее обсуждение различных аспектов этого шага приведено в следующем подразделе;
- декомпозировать каждый процесс текущего уровня DCFD либо в виде DCFD либо описать в виде Pspec. Каждый новый добавляемый на DCFD элемент необходимо помещать в Словарь Данных вместе со своим кратким текстовым описанием;
- параллельно с проведением декомпозиции анализировать требования потребителя, разделяя их на элементарные утверждения (обычно состоящие из одной фразы) и прослеживать, существует ли в модели процесс (и связанные с ним данные), соответствующий каждому элементарному требованию;
- каждый раз, когда сделано 2-3 уровня декомпозиции, проанализировать полученный результат на понятность и коректность с проверкой правильности балансировки данных. Разрешить все возникающие неоднозначности и пропуски в системных требованиях и, если это сразу не удается, то пометить их для дальнейшего исследования.
В результате анализа текста требований, относящихся к ПО, выделяется перечень абстрактных понятий предметной области проекта - сущностей. К их числу относятся реальные объекты, их свойства, события и различные взаимосвязи между ними. Производится первоначальная классификация и агрегация выделенных абстрактных понятий. Анализ можно рекомендовать проводить с помощью техники ER-диаграмм [ 1 ], которая далее служит основой для построения контекстной диаграммы. На этом этапе происходит отделение внутренних элементов системы от элементов внешнего мира и идентификация интерфейсов системы с внешним миром.
Проблема разделения данных и управления является одной из наиболее трудных проблем при построении модели. Таблицы 3.1 и 3.2 представляют классификацию, которой рекомендуется придерживаться при анализе текста требований.
Таблица 3.1
Вид физических данных на входе/выходе системы Рекомендуемая классификация при построении модели
Данные, представляющие ⌠непрерывные■ физические величины (например, скорость самолета, частота сигнала) поток данных Многозначные дискретные сигналы (например, фаза полета или режим функционирования) может рассматриваться и как поток данных и как поток управления.
Замечание. Если наряду с другими потоками данных участвует в вычислениях. то лучше рассматривать как поток данных. Если используется для управления (активации) процесса, то рассматривать как поток управления.Бинарные сигналы (например, сигнал ⌠в полете/на земле■, ⌠режим включен/выключен■) обычно - поток управления, хотя применимо предыдущее замечание. Таблица 3.2
Содержание процесса в системе Рекомендуемая классификация при построении модели
Процесс с входными/выходными данными, представляющие ⌠непрерывные■ физические величины или со смесью таковых с дискретными данными процесс обработки данных Процесс с входными/выходными дискретными данными обычно - управляющий процесс, но может рассматриваться и как процесс обработки данных, если все его входы\выходы рассматриваются как потоки данных, и если этот процесс не управляет другими процессами. Процесс с последовательностью состояний (т.е. его поведение изменяется в зависимости от некоторых событий) управляющий процесс, использующий STD или аналогичное описание В некоторых случаях бывает трудно классифицировать данные или процесс. В этом случае обычно любая интерпретация может оказаться вполне успешной и полезной в рамках проекта.
3.2. Стиль построения функциональной модели обработки данныхПостроение модели обработки данных можно считать перетрансляцией исходных системных требований на язык графических схем. В самом деле, системные требования отражаются в самом общем виде на контекстной диаграмме, которую саму можно считать другой формой этих требований. Процесс декомпозиции сам по себе не ⌠расширяет■ то описание, которое поставляет контекстная диаграмма, и каждый новый уровень описывает те же системные требования, только с более мелкой детализацией общих системных требований в большее множество более простых утверждений. Принципиально древовидная схема декомпозиционного графа позволяет избежать неоднозначности и повторений при такой ⌠трансляции■ и добиться, чтобы каждое частное требование появлялось на данной модели только в одном месте. Тогда ⌠горизонтальная■ взаимосвязь между некоторыми требованиями одного уровня логично выражается путем изображения потоков данных между соответствующими процессами.
Можно привести несколько полезных рекомендаций по проведению декомпозиции:
- минимизировать общее число потоков данных, диаграмм и процессов на каждой диаграмме;
- равномерно распределять потоки между процессами. Процесс с наибольшим числом потоков является ближайшим кандидатом на дальнейшую его декомпозицию - расщепление его либо на этом уровне либо на следующем. При этом полученные части некоторого процесса может оказаться естественным объединить с другими процессами;
- поток или процесс, который имеет не совсем подходящее имя, также является кандидатом на переразбиение, т.к. он возможно содержит ■лишние■ по смыслу части;
- насколько возможно концентрировать всю обработку некоторого входа или группы входов в небольшое число процессов.
Декомпозиция завершается написанием миниспецификаций процессов (PSPEC). Главная цель такой миниспецификации - описать, как выходы процесса генерируются из его входов, не больше и не меньше. Это означает упоминание каждого входа и выхода хотя бы однократно при отсутствии ссылки на любые другие потоки данных, которые есть в словаре (однако можно вводить ⌠локальные■ данные для упрощения описания). Каждое требование из системной спецификации должно быть отражено одним или несколькими утверждениями в Pspec. Кроме этого, конечно, может содержаться прямо не прослеживаемая к системным требованиям дополнительная информация, являющаяся как бы ⌠связующей■ для получения читаемого и понятного текста описания. Можно считать такую информацию производными требованиями, которые потребитель не считает для себя значащими, в то же время они крайне полезны как мостик для перехода к проектированию. Так или иначе, Pspec должен уместиться на одной странице (лучше - не более полстраницы), хотя гораздо важнее его содержание: правильно написанный Pspec содержит лишь другую форму представления требований, на основе анализа которых построена модель, и не содержит никаких деталей проекта.
3.3. Стиль построения модели управления
Несколько слов по поводу описания изменения потоков данных во времени. В модели принимается соглашение о том, что однажды произведенный некоторым процессом поток данных существует далее неизменным все время, пока этим процессом не будет изменено его значение или пока сам процесс не станет дезактивированным. Процесс, принимающий на вход этот поток, может прочитать его любое необходимое ему число раз. Однако в некоторых случаях необходимо представить сигнал, который обычно установлен в некое ⌠нулевое■, незначащее положение (аналог третьего состояния выхода некоторых микросхем), затем мгновенно устанавливается в некоторое ⌠осмысленное■ значение, которое однократно используется принимающим процессом, и затем (уже сам по себе) возвращается в исходное незначащее состояние. Это аналог события в рамках модели управления, но если мы хотим изобразить такой сигнал в рамках модели ообработки данных, мы должны помечать его специально установленным словом, например, ⌠установить■ (в то время как обычные потоки данных ⌠вычисляются■ или ⌠определяются■).Модель управления должна использоваться для описания логики, которая управляет состояниями (режимами) системы высокого уровня, и не опускаться до описания взаимодействия между примитивными процессами. Последнее может быть всегда выражено моделью процессов, управляемых данными: когда данные поступают на вход процесса, процесс выполняет свою задачу немедленно и мгновенно. Поэтому совершенно излишне снабжать эти данные сопутствующим им флагом, который имеет целью только ⌠включить■ процесс, когда данные будут готовы.
Основная тактика тогда сводится к следующему: всегда следует разрабатывать сначала модель обработки данных так долго, как это возможно. Не следует торопиться вводить модель управления без веских на то причин, и делать это только в крайнем случае, когда традиционное описание в виде процессов обработки данных оказывается неполным. Но даже в этом случае, сначала надо попытаться применить простейшую схему модели управления - в виде комбинационной логики (т.е. без памяти и без внутренних состояний процесса), что описывается, например, таблицей решений или логической формулой. Чтобы перейти к STD-описанию, мы должны убедиться, что кажущиеся необходимыми для описания внутренние состояния процесса не появляются уже в модели как отражение входных потоков данных от некоторого терминатора, а отражают некоторые условия или состояния внешнего мира, которые предстоит абстрагировать.
Например, если требуется ⌠рассчитать управляющие параметры для автопилота, когда появится запрос с пульта управления в нормальных условиях полета■, то несмотря на ⌠управленческую■ терминологию, такое требование выражается комбинационной схемой указанных условий без всякой памяти о предыдущих состояниях. И наоборот, если требуется ⌠выбрать конечный маршрут полета, когда самолет наберет высоту и перейдет к горизонтальному полету■, то естественно ввести два состояния системы : ⌠Набор высоты■ и ⌠Горизонтальный полет■, так как существенна информация о том, что произошел переход от набора высоты к горизонтальному полету (одного условия горизонтального полета недостаточно). В последнем примере не предусматривается никаких датчиков (терминаторов), генерирующих соответствующий поток данных/управления.
Вышеизложенная тактика основана на следующих соображениях:
- в самом лучшем случае может оказаться, что введение управляющей модели не понадобится вовсе. Надо убедиться, что требуемого эффекта нельзя достичь путем ⌠внутренне присущего■ некоторым данным их наличия или отсутствия в соответствующих режимах или условиях. Напомним, при этом соответствующий процесс не сможет производить свои выходы и фактически будет ⌠дезактивирован данными■. Если же начинать с разработки модели управления (или вести ее параллельно) то практически невозможно обнаружить то, что она не является необходимой;
- необходимо сперва установить, что именно мы собираемся контролировать, прежде чем решить, какую модель надо построить для этого;
- поскольку управляющие элементы сами зависимы от элементов данных (так, условие есть логическая функция от некоторых данных, событие - функция от изменения значения условия), то последние нуждаются в более раннем определении;
- процессы обработки данных должны выглядеть как ⌠черные ящики■, определяемые независимо от того, как, почему и когда они будут активированы. Напомним, что основой метода структурного анализа является принцип минимальной независимости процессов наряду с принципом их максимальной связности;
- область применения некоторых элементов управляющих процессов (в виде ⌠флагов■, ⌠битов■ и т.п.) фактически находится на границе требований и дизайна. Подчеркнем еще раз, что потребитель обычно не беспокоится о конкретных режимах функционирования системы, ограничиваясь только перечислением требуемых функций.
Исключением из изложенного выше принципа минимизации управляющей структуры является случай, когда система или ее часть служит для интенсивного управления какими либо исполнительными устройствами. В этом случае, управляющие процессы не столько используются для активации процессов внутри системы, сколько вырабатывают управляющие выходные воздействия, которые логичнее рассматривать как потоки управления.
Можно привести пример излишнего усложнения модели в случае, когда несколько процессов генерируют альтернативные выходы системы, только один из которых необходим в каждый момент времени. С ⌠практической■ точки зрения разработчика, только один процесс (подсознательно интерпретируемый им как некая программа) должен быть включен, остальные - выключены. Однако это описание скорее отвечает на вопрос ⌠как?⌠ и не может отражать системные требованиям. Более правильным будет интерпретация этих процессов как параллельно работающих и производящих некоторые выходы, которые являются внутренними и не идут на системный выход; тогда потребуется дополнительный процесс, который принимает все эти выходы и выбирает какой-то один из них уже на выход всей системы.
Если STD описание является все же необходимым, то его необходимо помещать на самый верхний уровень декомпозиции. Есть по крайней мере две причины для этого:
- любое нижне-уровневое ⌠локальное■ управление гораздо удобнее описывать внутри PSPEC с помощью общепринятых логических конструкций естественного языка, которые формализованы и для языков программирования. К ним относятся выражения с if, then, else, while, repeat и т.д. Подобное описание упрощает собственно графическую модель декомпозиции.
- поток управления (производимый или PSPEC или STD) не должен использоваться, прямо или косвенно, для управления процессом, являющимся предком этого же PSPEC (или STD). В противном случае в рамках нашей модели мы можем получить ⌠самовозбуждение■ указанного процесса. Помещая же STD на наиболее возможный уровень, мы упрощаем контроль за такими ситуациями, т.к. все управляющие сигналы идут уже как бы ⌠внутрь■, на более нижние уровни, и не могут деактивировать своих предков.
И последнее замечание. Как правило, диаграмма переходов в состояния моделирует поведение сложных объектов во времени. Кроме моделирования поведения самой системы может оказаться полезным моделирование поведения некоторых объектов внешнего мира.
3.4. Применение CASE-средства Select Yourdon Tool
Применение автоматизированных CASE-средств [ 1, 4, 5 ] позволяет переложить выполнение рутинных операций по графическому изображению и контролю получаемых графических структур на плечи компьютера и сосредоточиться именно на аспектах системного анализа проекта. Методология и средства CASE дают для описания, моделирования и построения программной системы общий графический язык, одновременно и достаточно строгий в формальном смысле и достаточно понятный для широкого круга специалистов. Ключевым моментом является также поддержка и документирование единой базы данных проекта, включая разнообразные средства контроля ее целостности и согласованности.
Рассмотрим возможность применения для проектирования программного обеспечения относительно недорогой CASE-системы Select Yourdon, разработанной фирмой Select Software Tools Ltd (England). Версия 3.10 работает под Windows 3.1 и выше, требует около 3 Мбайт свободной памяти в ОЗУ, 3 Мбайт на жестком диске и графику VGA [ 9 ]. Системa Select Yourdon поддерживает фазы анализа требований и проектирования программной системы, что покрывает полностью начальный период разработки вплоть до кодирования модулей. При этом поддерживаются следующие виды структурных методов (диаграмм):
- диаграммы отношения сущностей (ERD);
- диаграммы потоков данных и управления (DCFD), базирующиеся на нотации Yourdon/Ward & Mellor и Hatley;
- диаграммы переходов состояний (STD) ;
- миниспецификации процессов (PSpec);
- структурные диаграммы Константайна (Constantine);
- структурные диаграммы Джексона (Jackson).
К числу достоинств системы относится хорошо продуманный удобный графический редактор для создания диаграмм. Названия в процессе работы могут быстро вводиться из словаря данных на диаграммы с помощью встроенного браузера. Любую диаграмму система может распечатать на нескольких листах формата A4 (всего до 16 листов).
3.5. Пример задания на разработку системы
О достаточной практической глубине поддерживаемых теоретических методов говорит наличие в системе 28 различных типов элементов диаграмм и словаря. Так, на диаграмме DCFD возможно нарисовать терминатор, накопитель данных (store), функциональный и управляющий процессы, узловую и отцовскую точку, а также любой текстовой комментарий. Элементы DFD соединяют три вида потоков данных (discrete, control, continuous). Линия перехода между состояниями на STD помимо вызывающего его события позволяет отобразить пять типов сопутствующей переходу деятельности (action, activator, enable, disable, trigger), связанной с процессами и данными на других диаграммах. Диаграммы Константайна содержат пять типов программных конструкций (module, sub-system, library, contained, data area) и позволяют отразить последовательные, параллельные, условные и итеративные вызовы.
Наличие фильтра позволяет вести операции по выделенным группам элементов словаря данных, что полезно, в частности, при формировании отчетов. Всего система генерирует 14 различных отчетов, которые содержат иерархическую декомпозицию процессов и данных, кросс-референсную информацию, результаты контроля самосогласованности проекта, интерфейсы элементов и др. Эти отчеты имеют простую регулярную структуру и могут быть встроены в любой редактор (не только в Windows! ), а после некоторых усилий можно преобразовать эту информацию, например, в таблицу Word 6.0.
Следующий подраздел демонстрирует некоторые возможности диаграммной техники системы Select Yourdon.Спутниковая радионавигационная система GPS предназначена для непрерывного в реальном масштабе времени, глобального и высокоточного определения местоположения и времени различных потребителей на поверхности Земли, в воздушном и ближнем космическом пространстве [ 2 ]. В ее состав входят подсистема навигационных космических аппаратов (КА) и наземный комплекс управления. Определение конкретным потребителем своего местоположения и времени производится с помощью аппаратуры потребителя (или приемоиндикаторов). Приемоиндикатор позволяет принять навигационные сигналы с КА и переработать информацию, содержащуюся в них, в оценку координат и текущего времени.
Подсистема навигационных КА состоит из 32 КА с системными номерами от 1 до 32, симметрично расположенных на 6 орбитах высотой 20000 км. Сами орбиты, в свою очередь, симметрично охватывают поверхность Земли, имея одинаковый угол наклона в 55 градусов и разнесенных на 60 градусов по длине экватора. В любой момент в любой точке Земли видна по крайней мере четверка КА, необходимая для определения трехмерных координат и времени (обычно видно от 6 до 9 КА). Видимость КА определяется его геометрическим положением относительно антенны, не препятствующим распространению и приему сигнала.
Открытый навигационный сигнал (второе название - С/А-сигнал) имеет основную несущую 1575,42 Мгц и фазоманипулирован на 0/180 градусов. Фазовая манипуляция осуществляется псевдослучайной последовательностью (ПСП) с периодом 1 миллисекунда и тактовой частотой 1,023 Мгц. Один символ ПСП-кода имеет т.о. длительность около 1 микросекунды. Выделение полезной информации из подобных широкополосных сигналов при низком отношении сигнал/шум на антенном входе (напомним, что расстояние до КА составляет более 20000 км) возможен только при генерации в приемнике точной копии ПСП-кода и несущей принимаемого сигнала.
Навигационный сигнал содержит два вида полезной навигационной информации. Во первых, он несет внутреннюю оцифровку фазы ПСП-кода, а поскольку потребитель знает точно вид ПСП для конкретного КА, это позволяет ему выделить момент приема некоторой обусловленной фазы ПСП-кода (например, начало ПСП-кода) и на основе этого измерить задержку распространения сигнала относительно своей внутренней шкалы времени, причем сделать это точнее, чем длительность одного символа ПСП-кода. Из-за наличия произвольного на момент измерений рассогласования шкал времени потребителя и КА измеряется не дальность, а т.н. квазидальность, в которую кроме дальности входит и сдвиг временных шкал.
Далее, навигационный сигнал бинарно фазоманипулирован так называемой служебной информацией (СИ) с частотой 50 Hz. СИ организована в кадры, длящиеся 30 секунд и содержащие 1500 бит информации. Каждый кадр разделен на 5 подкадров по 300 бит, каждый подкадр состоит из 10 слов по 30 бит. Кадр СИ помимо телеметрии и контрольной информации содержит следующую полезную информацию для потребителя:
- альманах системы, содержащий местоположение и привязку временных шкал всех КА на определенный момент времени с точностью, достаточной для быстрого поиска сигналов КА;
- эфемериды КА, содержащие аналогичную информацию, но с более высокой точностью и более высоким темпом ее обновления.
Эфемериды (наряду с измерениями квазидальности) используются для получения высокоточной оценки положения и времени (или сдвига временной шкалы) потребителя.
3.5.2. Системные требования на разработку приемоиндикатора
Рассмотрим типичные минимальные системные требования, которые может выдвинуть потребитель на функционирование четырехканального приемника спутниковой радионавигационной системы GPS, который мы будем называть ПРИН-1 (ПРиемоИНдикатор). Указанные требования, пронумерованные ниже, подходят под класс простейшей карманной аппаратуры, рассчитанной на статического потребителя, не требующего никаких специальных сервисных функций, кроме одной - возможности определять свое местоположение и текущее время. Все требования пронумерованы, определения и пояснения используемых в требованиях технических понятий выделены курсивом.
- ПРИН-1 должна осуществлять самопроверку работоспособности при вводе потребителем команды КОНТРОЛЬ.
- Если в результате самопроверки обнаружена неисправность, то ПРИН-1 должен выдать потребителю сообщение об этом и повторить самопроверку.
- Если в результате самопроверки неисправностей не обнаружено, то ПРИН-1 должен выдать потребителю сообщение об успешной проверке и перейти к синхронизации сигналов КА.
- ПРИН-1 должен осуществлять синхронизацию сигналов одновременно от 4 космических аппаратов (КА) системы GPS.
Синхронизация сигнала КА достигается путем генерации точной копии его ПСП-кода и несущей в виде опорного сигнала и проверяется путем измерения уровня корреляции между принимаемым и опорным сигналом.- ПРИН-1 должен декодировать текущую эфемеридную информацию из сигналов синхронизированных КА.
- ПРИН-1 должен измерять квазидальности одновременно до 4 синхронизированных КА.
Квазидальность состоит из суммы фактической дальности между КА и антенной ПРИН-1 и расхождением шкал времени КА и ПРИН-1, пересчитанных в одинаковые физические единицы.- ПРИН-1 должна принимать вводимые потребителем (в произвольном порядке) начальные данные: начальные координаты местоположения и текущее время, если соответствующие данные не были вычислены из сигналов КА.
- Если вводимая с пульта информация уже вычислена из сигналов КА, то она должна игнорироваться с выдачей предупреждения потребителю.
- Если в момент начальной синхронизации сигналов видно более 4 КА, то ПРИН-1 должна выбирать 4 КА с наилучшим геометрическим фактором.
Для вычисления геометрического фактора необходимы альманах или эфемериды (для расчета положения КА) и оценка местоположения (введенная потребителем или вычисленная по квазидальностям). Геометрический фактор созвездия КА оценивает точность вычисления координат.- После того как были введены новые начальные данные, ПРИН-1 должна перерассчитать по этим данным четверку видимых КА с наилучшим геометрическим фактором.
- Если отсутствует или альманах или оценка местоположения/времени, то ПРИН-1 должна искать сигналы КА меняя опорный сигнал в максимально допустимом для GPS сигнала частотно-фазовом диапазоне, начиная (для определенности) с наименьших системных номеров и переходя к следующему системному номеру, если приемлемый уровень корреляции не достигнут при однократном проходе максимального диапазона.
В систему GPS входят 32 КА с номерами от 1 до 32.- После окончания синхронизации выбранных 4 КА и декодирования эфемерид от этих КА, ПРИН-1 должна вычислять трехмерные координаты местоположения (геодезические широту, долготу и высоту) на основе измеренных квазидальностей и декодированных эфемерид от 4 КА.
- В условиях когда имеется полный неустаревший альманах GPS, время до первого вычисления трехмерных координат не должно превышать 2 минут.
- Если альманах отсутствует или устарел, время до первого вычисления трехмерных координат не должно превышать 10 минут.
Альманах может отсутствовать при самом первом включении ПРИН-1. При необновлении альманаха в течение порядка нескольких недель (например, при консервации ПРИН-1), данные альманаха устаревают.- Вычисление трехмерных координат местоположения, когда оно становится возможным, должно происходить с темпом не реже раз в секунду.
- Совместно с вычислением координат должен вычисляться геометрический фактор созвездия КА, по которому производится вычисление координат.
- Вычисленные трехмерные координаты местоположения (геодезические широта, долгота и высота) и геометрический фактор должны отображаться на дисплее потребителя не позднее чем через 0.5 секунды после измерения квазидальности.
- Если полный альманах отсутствует или устарел, то совместно с вычислением координат должен производиться прием полного альманаха GPS.
Полный альманах содержит данные на все 32 КА.- Альманах на систему должен сохраняться после выключения питания ПРИН-1.
- По крайней мере раз в 5 минут ПРИН-1 должна перевыбирать для последующей синхронизации на основе полного альманаха GPS четверку видимых КА с наилучшим геометрическим фактором.
3.5.3.1. Выделение требований на режимы работы
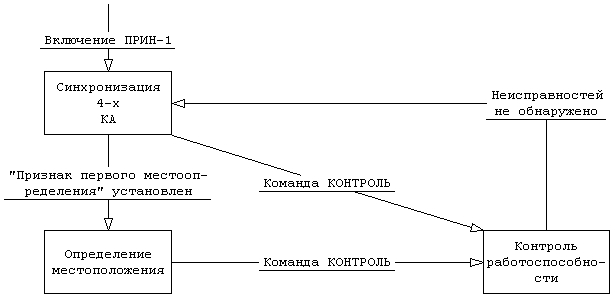
Первые три системных требования требуют наличие режима контроля работоспособности. Кроме этого удобно (хотя и не обязательно) выделить отдельно режим синхронизации КА, поскольку есть системные требования на длительность синхронизации КА при различных условиях (см. требования 13, 14). Диаграмма переходов в состояния представлена на рис. 3.1.
Рис. 3.1 Диаграмма переходов в состояния для приемоиндикатора.
3.5.3.2. Выделение требований на временные интервалыАнализ требований на интервалы времени в системе производится с помощью таблицы 3.3.
Таблица 3.3
Условие Раннее событие Позднее событие Интервал времени между событиями Номер системного требования Потребитель вводит все начальные данные Окончание ввода всех начальных данных Первое местоопределение по квазидальностям 2 минуты 13 Потребитель не вводит все начальные данные Включение питания Первое местоопределение по квазидальностям 10 минут 14 Синхронизировано 4 КА и для них декодирована СИ Каждый момент измерения квазидальностей Выдача потребителю очередной ⌠Оценки местоположения/времени■ 0.5 секунды 17
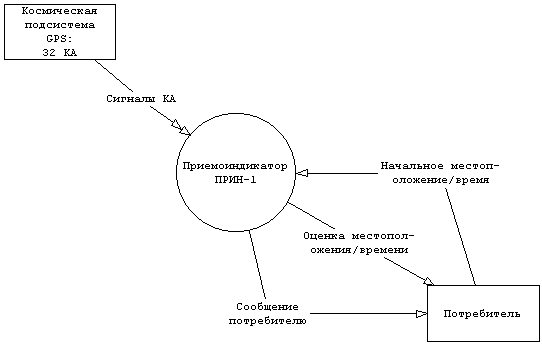
3.5.3.3. Выделение функциональных требований и построение структурной моделиВ системных требованиях можно выделить следующие терминаторы: космическая подсистема GPS, состоящая из 32 космических аппаратов (КА) и потребитель. В результате можно построить контекстную диаграмму, показанную рис. 3.2.
Рис. 3.2 Контекстная диаграмма приемоиндикатора.
Далее можно выделить пять основных функциональных процессов (или сокращенно - функций) при работе системы (в скобках приведены ссылки на системные требования):
- синхронизировать сигналы КА или, что эквивалентно, генерировать опорные сигналы (4, 11)
- декодировать служебную информацию (5, 18)
- измерить квазидальности (6)
- вычислить оценку местоположения/времени (12, 15. 16)
- выбрать КА для синхронизации (9, 20)
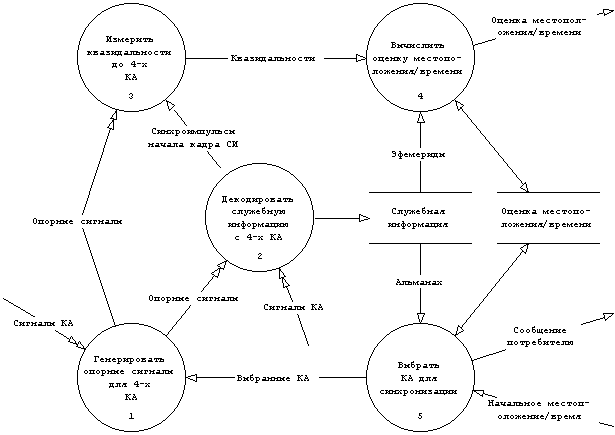
Соответствующая диаграмма первого уровня декомпозиции приведена на рис. 3.3.
Рис. 3.3 Диаграмма потоков данных первого уровня декомпозиции.
Отметим, что такие функции как ввод начальных данных и выдача различных сообщений на дисплей (7, 8, 17) не учитываются на данном этапе, т.к. относятся к интерфейсным функциям. Требование на сохранение данных альманаха после отключения питания (19) не попадает в системные функциональные требования, а является требованием к дальнейшему проектированию системы.
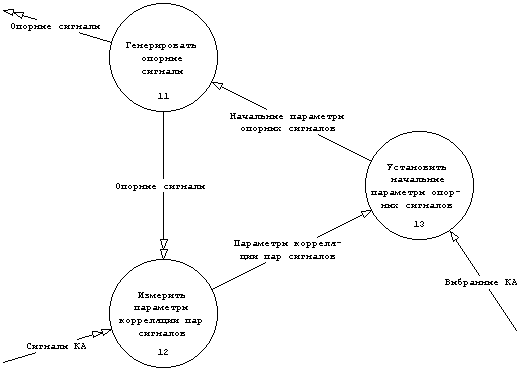
Первые три процесса (функции) декомпозируются еще на один уровень, как показано на рис. 3.4 - 3.14, начиная с декомпозиции процесса ⌠Генерировать опорные сигналы 4-х КА■. Наряду с DFD приведены мини-спецификации процессов нижнего уровня со ссылками на пункт системных требований. Если нет прямой ссылки, то приводится комментарий, разъясняющий необходимость присутствия того или иного действия.
Рис. 3.4 DFD процесса ⌠Генерировать опорные сигналы 4-х КА■.
@IN = Начальные параметры опорных сигналов
@OUT = Опорные сигналы
@PSPEC Генерировать Опорные сигналы
Генерировать "Опорные сигналы",
имеющие в качестве начальных параметров "Начальные параметры опорных сигналов" (4).
Рис. 3.5 Спецификация процесса ⌠Генерировать Опорные сигналы■
@IN = Опорные сигналы
@IN = Сигналы КА
@OUT = Параметры корреляции пар сигналов
@PSPEC Измерить параметры корреляции пар сигналов
Измерить "Параметры корреляции пар сигналов" между "Опорными сигналами" и "Сигналами КА" (4).
Рис. 3.6 Спецификация процесса ⌠Измерить параметры корреляции пар сигналов■
@IN = Выбранные КА
@IN = Параметры корреляции пар сигналов
@OUT = Начальные параметры опорных сигналов
@PSPEC Установить начальные параметры опорных сигналов
Если при первом включении не были установлены "Выбранные КА", то
Установить "Начальные параметры опорных сигналов" для КА с наименьшими системными номерами,
Затем, если "Начальные параметры опорных сигналов" прошли максимально возможный диапазон и "Параметры корреляции пар сигналов" показывают отсутствие приемлемой корреляции, то
Установить "Начальные параметры опорных сигналов"
для КА со следующим системным номером (11).
Повторять для каждого нового множества "Выбранных КА":
Установить "Начальные параметры опорных сигналов" для "Выбранных КА" (9, 10, 20),
Повторять для каждого приходящего "Параметры корреляции пар сигналов"
Улучшить корреляцию, скорректировав "Начальные параметры опорных сигналов", используя "Параметры корреляции пар сигналов" (см. комментарий).
@COMMENT
Необходимость постоянной подстройки опорного сигнала обусловлена движением КА, что даже при неподвижном потребителе приводит к допплеровскому сдвигу несущей и временному сдвигу принимаемого ПСП-кода.
Рис. 3.7 Спецификация процесса ⌠Установить начальные параметры опорных сигналов■
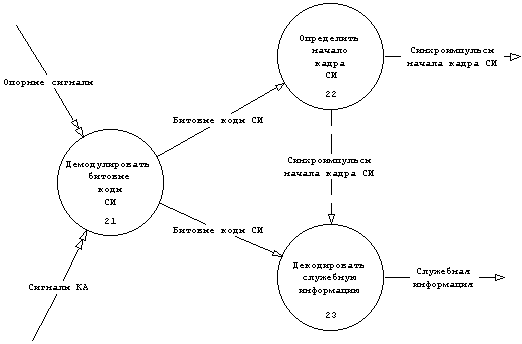
Рис. 3.8 DFD процесса ⌠Декодировать Служебную информацию 4-х КА■
@IN = Опорные сигнала
@IN = Сигналы КА
@OUT = Битовые коды СИ
@PSPEC Демодулировать битовые коды СИ
Демодулировать "Битовые коды СИ" из "Сигналов КА",
используя для снятия модуляции "Опорные сигналы"
Рис. 3.9 Спецификация процесса ⌠Демодулировать битовые коды СИ■
@IN = Битовые коды СИ
@IN = Синхроимпульсы начала кадра СИ
@OUT = Служебная информация
@PSPEC Декодировать служебную информацию
Выделить субкадры в "Битовых кодах СИ" для 4-х сигналов КА
используя "Синхроимпульсы начала кадра СИ".
Затем, декодировать "Служебную информацию" из субкадров (5, 18).
Рис. 3.10 Спецификация процесса ⌠Декодировать служебную информацию■
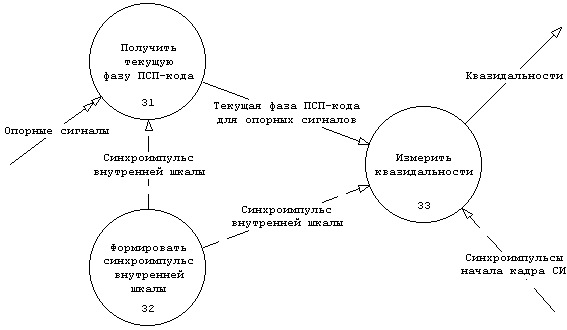
Рис. 3.11 DFD процесса ⌠Измерить квазидальности до 4-х КА■
@IN = Синхроимпульс внутренней шкалы
@IN = Опорные сигналы
@OUT = Текущая фаза ПСП-кода для опорных сигналов
@PSPEC Получить текущую фазу ПСП-кода
В момент прихода "Синхроимпульса внутренней шкалы"
установить "Текущую фазу ПСП-кода для опорных сигналов" по текущему состоянию "Опорных сигналов".
Рис. 3.12 Спецификация процесса ⌠Получить текущую фазу ПСП-кода■
@OUT = Синхроимпульс внутренней шкалы
@PSPEC Формировать синхроимпульс внутренней шкалы
Повторять с темпом не реже 1 раз в секунду:
Установить "Синхроимпульс внутренней шкалы" (15).
Рис. 3.13 Спецификация процесса ⌠Формировать синхроимпульс внутренней шкалы■
@IN = Текущая фаза ПСП-кода для опорных сигналов
@IN = Синхроимпульс внутренней шкалы
@IN = Синхроимпульсы начала кадра СИ
@OUT = Квазидальности
@PSPEC Измерить квазидальности
Фиксировать момент прихода каждого "Синхроимпульса начала кадра СИ" с точностью до миллисекунды.
Если пришло ровно четыре различных "Синхроимпульса начала кадра СИ", то:
в момент прихода "Синхроимпульса внутренней шкалы"
вычислить "Квазидальности" из "Текущей фазы ПСП-кода для опорных сигналов"
с учетом момент прихода каждого "Синхроимпульса начала кадра СИ" (6)
Рис. 3.14 Спецификация процесса ⌠Измерить квазидальности■
Приведем теперь краткие пояснения проведенной на рис. 3.8 декомпозиции. Опорный сигнал отражает информацию о несущей и ПСП-коде принимаемого сигнала КА, однако принципиально не может содержать информации о СИ, т.к. СИ несет информацию, не известную заранее потребителю. Поэтому необходимо:
- демодулировать СИ от несущей и ПСП-кода;
- синхронизировать непрерывный битовый код СИ, найдя в нем начало кадра. Заметим, что это не может произойти ⌠автоматически■ при демодуляции, т.к. начало кадра не окрашено каким либо физическим импульсом само по себе, а отображается лишь некоторой логической комбинацией некоторой последовательности битового кода;
- декодировать этот код в собственно СИ, пользуясь известной заранее потребителю структурой кадра СИ, состоящего из слов и подкадров.
Поясним также суть проведенной на рис. 3.11 декомпозиции. Шкала времени на каждом КА синхронна с моментом "начала кадра СИ" передаваемого сигнала. Именно этот момент определяется в приходящем сигнале КА функцией "Декодировать служебную информацию с 4-х КА" и помечается "Синхроимпульсом начала кадра СИ". Точность этого синхроимпульса не может быть выше, чем период ПСП-кода (т.е. 1 миллисекунда). Получить более точный отсчет квазидальности в произвольный (для приходящего сигнала!) момент "Синхроимпульса внутренней шкалы" возможно лишь используя внутреннюю информацию о фазе ПСП-кода внутри его периода.
На рис. 3.15, 3.16 приведены мини-спецификации оставшихся двух процессов верхнего уровня: ⌠Вычислить оценку местоположения/времени■ и ⌠Выбрать КА для синхронизации■.
@IN = Квазидальности
@IN = Эфемериды
@OUT = Оценка местоположения/времени
@PSPEC Вычислить оценку местоположения/времени
Установить "Признак первого местоопределения".
Повторять с темпом не реже раз в 5 минут (20):
Обновить "Геометрический фактор" созвездия КА на основе "Эфемерид" и текущего "Местоположения" (16).
Повторять с темпом не реже раз в секунду (15):
Обновить "Местоположение" и "Время" на основе текущих "Квазидальностей" и
"Эфемерид" (12).
Затем, выдать на дисплей "Оценку местоположения/времени" из текущих "Местоположения", "Времени", "Геометрического фактора" (17),
Рис. 3.15 Спецификация процесса ⌠Вычислить оценку местоположения/времени■
@IN = Начальное местоположение/время
@IN = Альманах
@INOUT = Оценка местоположения/времени
@OUT = Выбранные КА
@OUT = Сообщение оператору
@PSPEC Выбрать КА для синхронизации
Если "Начальное местоположение/время" вводится в режиме "Синхронизация 4-х КА", то
Установить "Местоположение" и "Время" из "Начального местоположения/времени" (7).
Если "Начальное местоположение/время" вводится в режиме "Определение местоположения", то
Выдать на дисплей "Сообщение оператору" об игнорировании введенных данных (8).
Если имеется "Местоположение" и "Время" из "Оценки местоположения/времени" и "Альманах", то
Повторять для каждых новых начальных данных (10) и по крайней мере раз в 5 минут (20):
Выбрать 4 видимых КА с наилучшим геометрическим фактором,
используя текущие "Альманах" и "Оценку местоположения/времени",
затем установить их в "Выбранные КА" (9).
Рис. 3.16 Спецификация процесса ⌠Выбрать КА для синхронизации■
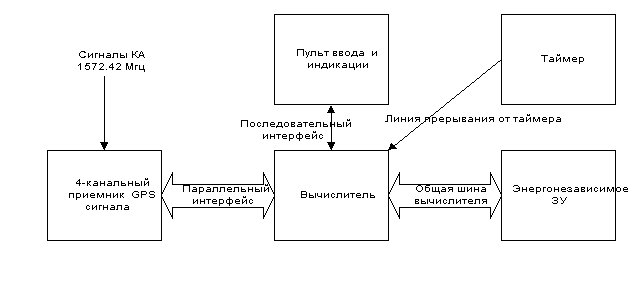
3.5.3.4. Выбор архитектурной модели системыПредположим, что в результате анализа экономических соображений и состояния развития современной элементной базы принято решение проектировать наше устройство из 5 архитектурных модулей, как показано на рис. 3.17.
Рис. 3.17 Архитектура приемоиндикатора
Архитектурный модуль ⌠4-канальный приемник GPS сигнала■ аппаратными средствами реализует следующие функции (в скобках указаны идентификационные номера на диаграммах):
- ⌠Генерировать опорные сигналы■ (11)
- ⌠Измерить параметры корреляции пар сигналов■ (12)
- ⌠Демодулировать битовые коды СИ ■(21)
- ⌠Получить текущую фазу ПСП-кода ■(31)
Канал параллельного интерфейса между ⌠4-канальным приемником GPS сигнала■ и ⌠Вычислителем■ передает следующие потоки данных:
- ⌠Начальные параметры опорных сигналов■ от вычислителя
- ⌠Битовые коды СИ■ от приемника
- ⌠Параметры корреляции пар сигналов■ от приемника
- ⌠Текущая фаза ПСП-кода для опорных сигналов■ от приемника
Архитектурный модуль ⌠Таймер■ реализует функцию ⌠Формировать синхроимпульс внутренней шкалы (32)■. По каналу межмодульной связи ⌠Линия прерывания от таймера■ передается управляющий поток ⌠Синхроимпульс внутренней шкалы■.
Архитектурный модуль ⌠Энергонезависимое ЗУ■ служит для хранения альманаха при выключения питания, реализуя тем самым системное требование (19). По общей с вычислителем шине передается альманах в обоих направлениях. Здесь мы имеем отщепление от накопителя ⌠Служебная информация■ части, реализуемой аппаратно отдельным архитектурным модулем. В то же время хранение эфемерид остается внутри модуля ⌠Вычислитель■, который реализует все оставшиеся системные функции программным путем.
Интерфейс с потребителем реализуется посредством архитектурного модуля ⌠Пульта ввода и индикации■. Он преобразует данные, вводимые потребителем на клавиатуре в информацию, передаваемую по последовательному интерфейсу в вычислитель, и обратно, от вычислителя в форму, воспринимаемую потребителем (например, цифровое табло). Выбор здесь именно последовательного, а не параллельного интерфейса (как в случае связи с приемником) возможен из-за небольшой скорости обработки информации человеком.3.5.3.5. Выбор архитектуры каналов взаимодействия модулейСами по себе действия, описанные выше миниспецификациями процессов в рамках терминологии потоков данных системного уровня не изменяются. Однако учет архитектурной реализации каналов, передающих потоки данных для этих процессов требует детализации этих потоков, или их декомпозиции с учетом принимаемых проектных решений для интерфейса программ с аппаратурой.
Предположим, что либо из описания готового архитектурного модуля (например, некоторой серийной микросхемы, уже выполняющей функции 4-канального приемника GPS-сигналов) либо из согласованного с разработчиком задания на разработку такого модуля было принято решение о том, что потоки данных от/к ⌠Приемнику сигналов■ для каждого канала представляются отдельными регистрами. Имена потоков данных от конкретных регистров переобозначены заглавными буквами с добавлением числового индекса(номера канала) и с подчеркиванием, например, ⌠ТЕКУЩАЯ_ФАЗА_ПСП_КОДА_1■, ⌠БИТОВЫЙ_КОД_СИ_3■ и т.д. Итак, можно говорить о декомпозиции, например, потока данных ⌠Битовые коды СИ■, который является элементарным на уровне системной модели, в виде BNF на уровне модели требований к программам:
БИТОВЫЕ_КОДЫ_СИ = БИТОВЫЙ_КОД_СИ_1 + БИТОВЫЙ_КОД_СИ_2 + БИТОВЫЙ_КОД_СИ_3 + БИТОВЫЙ_КОД_СИ_4.
Отметим, что слитность написания имен позволяет далее без всяких изменений использовать их в программах. Кроме этого, рекомендуется их несколько сократить с сохранением ясной прослеживаемости к соответствующим системным понятиям.
Далее, предположим, что для реализации потоков данных ⌠Сообщение оператору■ и ⌠Оценка местоположения/времени■ необходимо сформировать ASCII-строку с символьным сообщением и послать ее байт за байтом в соответствии со стандартным протоколом RS-232 на ⌠Пульт ввода и индикации■. Назовем соответствующий элемент данных как ⌠ВЫХОДНАЯ_ASCII_СТРОКА■. Прием данных из последовательному каналу должен начинаться с приема определенного байта, чтобы позволить вычислителю различить вид дальнейшей байтовой информации, передаваемой далее цифрами с разделительной точкой:
- передача координат широты - ⌠B■<широта в градусах и минутах>
- передача координат долготы - ⌠L■<долгота в градусах и минутах>
- передача времени ⌠Т■<время в часах и минутах>
- команда КОНТРОЛЬ - одиночный символ ⌠К■.
Тогда мы имеем на входе ⌠ИДЕНТИФИКАТОР_ВВОДА■ со значениями ⌠B■, ⌠L■, ⌠T■, ⌠K■ и в первых трех случаях еще и элемент данных ⌠ВХОДНАЯ_ASCII_СТРОКА■. Можно ввести составной поток данных:
ВХОДНЫЕ_ДАННЫЕ = ИДЕНТИФИКАТОР_ВВОДА + (ВХОДНАЯ_ASCII_СТРОКА).
⌠Синхроимпульс внутренней шкалы■ преобразуется с учетом аппаратной реализации в управляющий поток ⌠ПРЕРЫВАНИЕ ОТ ТАЙМЕРА■.
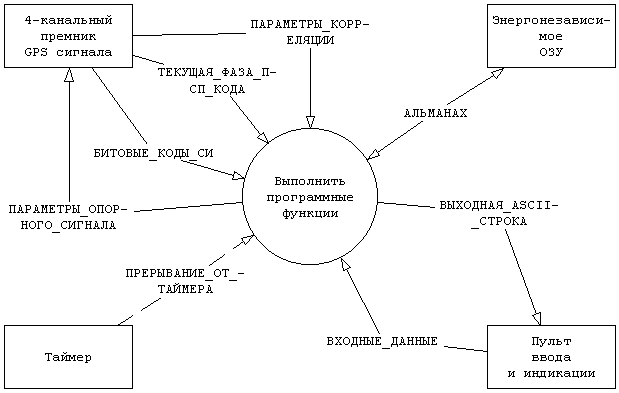
3.5.3.6. Построение модели требований, относящихся к программамСохраняя имена архитектурных модулей для терминаторов программной модели, можно построить контекстную диаграмму, показанную на рис. 3.18.
Рис. 3.18 Контекстная диаграмма функций, выполняемых программой
Перебалансировка потоков данных обычно приводит к перебалансировке функций. В конечном итоге может получиться следующая диаграмма верхнего уровня (рис. 3.19).
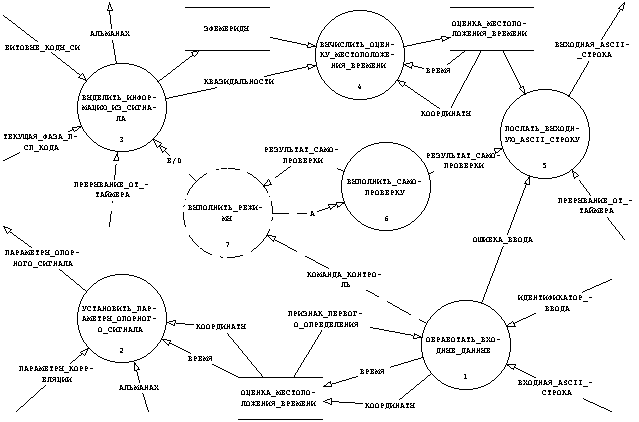
Рис. 3.19 DFD верхнего уровня декомпозиции программных функций
С приведенной диаграммой непосредственно связана диаграмма переходов в состояния, формально являющаяся дочерней для управляющего процесса ⌠ВЫПОЛНИТЬ_РЕЖИМЫ■. Она приведена на рисунке 3.20.
Рис. 3.20 STD для программного обеспечения приемоиндикатора
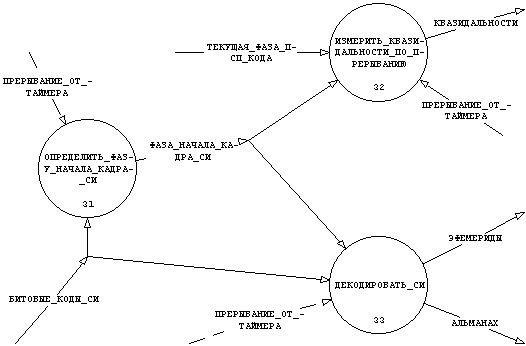
При перебалансировке процессов мы укрупнили три процесса обработки сигнала, реализуемые программно в рамках нашей архитектуры в один - ⌠ВЫДЕЛИТЬ_ИНФОРМАЦИЮ_ИЗ_СИГНАЛА■. Кроме этого информация, поставляемая ⌠Синхроимпульсами начала кадра СИ■ теперь поставляется потоком данных ⌠ФАЗА НАЧАЛА КАДРА СИ■, отсчитываемой от момента прихода ⌠ПРЕРЫВАНИЯ_ОТ_ТАЙМЕРА■. Учитывая это изменение, мы получим декомпозицию процесса ⌠ВЫДЕЛИТЬ_ИНФОРМАЦИЮ_ИЗ_СИГНАЛА■ в следующем виде (см. рис. 3.21).
Рис. 3.21 DFD процесса ⌠ВЫДЕЛИТЬ_ИНФОРМАЦИЮ_ИЗ_СИГНАЛА■
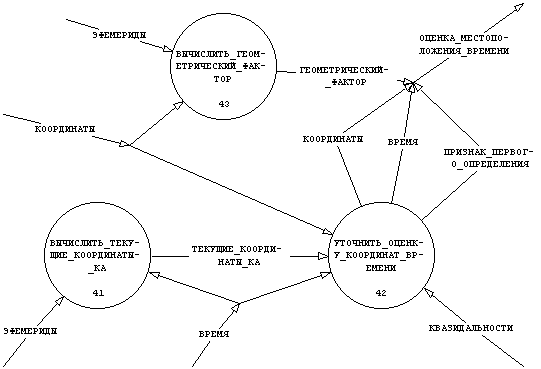
Детальное рассмотрение формирования составляющих потока ⌠ОЦЕНКА_МЕСТОПОЛОЖЕНИЯ_ВРЕМЕНИ■ приводит к декомпозиции процесса ⌠ВЫЧИСЛИТЬ_ОЦЕНКУ_МЕСТОПОЛОЖЕНИЯ_ВРЕМЕНИ■ как показано на рис. 3.22.
Рис. 3.22 DFD процесса ⌠ВЫЧИСЛИТЬ_ОЦЕНКУ_МЕСТОПОЛОЖЕНИЯ_ВРЕМЕНИ■
Мы не будем загромождать наш модельный пример проведением дальнейшей декомпозиции и полным множеством миниспецификаций процессов нижнего уровня. Помимо дополнительного места это потребует разъяснения особенностей обработки GPS-сигнала и проведения навигационных местоопределений. Приведем лишь миниспецификации процессов, которые выглядят уже на приведенных диаграммах достаточно простыми и законченными - ⌠ОБРАБОТАТЬ_ВХОДНЫЕ_ДАННЫЕ■ и ⌠ПОСЛАТЬ_ВЫХОДНУЮ_ASCII_СТРОКУ■. Отметим, что вполне логично далее, на этапе дизайна программ, реализовать каждую из этих функций в виде отдельного архитектурного программного модуля, исходя из приведенных миниспецификации.
@IN = ВХОДНАЯ_ASCII_СТРОКА
@IN = ИДЕНТИФИКАТОР_ВВОДА
@IN = ПРИЗНАК_ПЕРВОГО_ОПРЕДЕЛЕНИЯ
@OUT = КОМАНДА_КОНТРОЛЬ
@OUT = КООРДИНАТЫ
@OUT = ВРЕМЯ
@OUT = ОШИБКА_ВВОДА
@PSPEC ОБРАБОТАТЬ_ВХОДНЫЕ_ДАННЫЕ
Повторять с темпом поступления ВХОДНЫХ_ДАННЫХ в зависимости от значения ИДЕНТИФИКАТОРА_ВВОДА:
Если "K", то
Установить КОМАНДА_КОНТРОЛЬ,
Если "B", то
если ПРИЗНАК_ПЕРВОГО_ОПРЕДЕЛЕНИЯ не установлен, то
Установить в КООРДИНАТЫ широту, заданную ВХОДНОЙ_ASCII_СТРОКОЙ,
иначе
Установить ОШИБКА_ВВОДА = "Введенная широта игнорируется".
Если "L", то
если ПРИЗНАК_ПЕРВОГО_ОПРЕДЕЛЕНИЯ не установлен, то
Установить в КООРДИНАТЫ долготу, заданную ВХОДНОЙ_ASCII_СТРОКОЙ,
иначе
Установить ОШИБКА_ВВОДА = "Введенная долгота игнорируется".
Если "T", то
если ПРИЗНАК_ПЕРВОГО_ОПРЕДЕЛЕНИЯ не установлен, то
Установить ВРЕМЯ, заданное ВХОДНОЙ_ASCII_СТРОКОЙ,
иначе
Установить ОШИБКА_ВВОДА = "Введенное время игнорируется".
Если любое другое значение, то
Установить ОШИБКА_ВВОДА = "Ошибка интерфейса".
Рис. 3.23 Спецификация процесса ⌠ОБРАБОТАТЬ_ВХОДНЫЕ_ДАННЫЕ■
@IN =ОЦЕНКА_МЕСТОПОЛОЖЕНИЯ_ВРЕМЕНИ
@IN = ОШИБКА_ВВОДА
@IN = ПРЕРЫВАНИЕ_ОТ_ТАЙМЕРА
@IN = РЕЗУЛЬТАТ_САМОПРОВЕРКИ
@OUT = ВЫХОДНАЯ_ASCII_СТРОКА
@PSPEC ПОСЛАТЬ_ВЫХОДНУЮ_ASCII_СТРОКУ
Повторять для каждого РЕЗУЛЬТАТА_САМОПРОВЕРКИ:
Установить ВЫХОДНУЮ_ASCII_СТРОКУ = РЕЗУЛЬТАТ_САМОПРОВЕРКИ.
Повторять для каждой ОШИБКИ_ВВОДА:
Установить ВЫХОДНУЮ_ASCII_СТРОКУ = ОШИБКА_ВВОДА.
Повторять с темпом прихода ПРЕРЫВАНИЯ_ОТ_ТАЙМЕРА:
Сформировать ВЫХОДНУЮ_ASCII_СТРОКУ из всех доступных данных
ОЦЕНКИ_МЕСТОПОЛОЖЕНИЯ_ВРЕМЕНИ,
Рис. 3.24 Спецификация процесса ⌠ПОСЛАТЬ_ВЫХОДНУЮ_ASCII_СТРОКУ■
3.5.4. Рекомендуемое содержание документа ⌠Требования к ПО■
Ниже на рис. 3.25 приводится оглавление документа, который содержит требования к ПО, модель которых разработана в примере.
1. Введение
2. Анализ системных требований и системного дизайна.
2.1 Обзор модели системных требований.
2.2 Обзор архитектуры системы.
2.3 Выделение системных функций, реализуемых программными средствами.
3. Описание программно-аппаратного интерфейса.
3.1 Ограничения используемого вычислителя, накладываемые на ПО.
3.2 Параллельный интерфейс с приемником GPS сигнала.
3.3 Последовательный интерфейс с пультом ввода и индикации.
3.4 Описание линии прерывания от таймера.
3.5 Описание протокола взаимодействия с энергонезависимым ЗУ.
4. Функциональные требования
4.1 Общая организация работы.
4.1.1 Требования на режимы работы программ.
4.1.2 Обзор функциональной декомпозиции программ.
4.2 Обработка входных данных.
4.3 Установка параметров опорного сигнала.4.4 Выделение информации из сигнала.
4.4.1 Определение фазы начала кадра СИ.
4.4.2 Измерение квазидальности.
4.4.3 Декодировка СИ.
4.5 Вычисление оценки местоположения и времени.
4.5.1 Вычисление текущих координат КА.
4.5.2 Уточнение оценки координат и времени.
4.5.3 Вычисление геометрического фактора.
4.6 Формирование выходного сообщения.
4.7 Выполнение самопроверки.
4.8 Требования на временные интервалы.Приложения
А. Модель системных требований.
Б. Модель программных требований, включая словарь данных.
В. Таблица прослеживаемости к системным требованиям.
Г. Перечень использованных сокращений.
Рис. 3.24 Примерное оглавление документа ⌠Требования к ПО■
⌠Введение■ содержит идентифицирующий материал и варианты его структуры уже достаточно подробно рассматривались ранее.
Подраздел ⌠Обзор модели системных требований■ содержит ссылку на ⌠Приложение А■ и некоторые разъяснения по поводу проведенного моделирования в тех местах, которые не прямо вытекают из текста системных требований. Подраздел ⌠Обзор архитектуры системы■ содержит иллюстрацию уже выбранной архитектуры системы с описанием физической реализации архитектурных модулей и каналов взаимодействия между ними.
Подраздел ⌠Выделение системных функций, реализуемых программными средствами■ классифицирует все системные функции на реализуемые аппаратно (с их кратким со ссылками на их описание в других документах если они есть) и программно. Раздел ⌠Описание программно-аппаратного интерфейса■ описывает принятые решения по протоколам, форматам, частоте обновления данных во всех интерфейсных для ПО (и как правило, чисто внутренних для системы в целом) каналах обмена данными. Сюда входят также и линии аппаратных прерываний вычислителя.Далее начинается раздел, содержащий собственно требования на ПО. Заметим, что хотя названия параграфов и сама структура раздела ⌠Функциональные требования■ определяются построенной выше моделью, необязательно отождествлять соответствующие названия параграфов и имена процессов. Гораздо важнее сохранить совпадение имен в модели и имен в программе, что накладывает определенные ограничения на построение имен модели (например, слитность имен). Необходимо также обеспечить сквозную прослеживаемость применяемых технических понятий. Например, название подраздела ⌠4.2 Обработка входных данных■ в документе требований на программу прослеживается к имени процесса ⌠ОБРАБОТАТЬ ВХОДНЫЕ ДАННЫЕ■ с входным потоком ⌠ВХОДНЫЕ ДАННЫЕ■ в программной модели. Далее можно проследить указанный элемент к потоку данных ■Начальное местоположение/время■ в системной модели и далее к системным требованиям (7) и (8) с терминологией ⌠... должна принимать вводимые потребителем (в произвольном порядке) начальные данные ...■ и ⌠Если вводимая с пульта информация ...■.
В случае полной прослеживаемости непротиворечивость информационной модели, проверяемая CASE-средствами, гарантирует и непротиворечивость требований к ПО.